Make Java - Performance
Teil 7
Implementierung mit Java
Wir werden uns im folgenden den Javaspezifischen Optimierungen zuwenden. Wie in den anderen Abschnitten, liegt auch hier der Schwerpunkt auf die Beschleunigung der Ausführungsgeschwindigkeit. An geeigneter Stelle werden jedoch immer wieder Einwürfe zu den anderen Performanceeigenschaften einer Lösung fallen. Ein für Bytecode Compiler optimaler Code, kann mit JIT Compilern langsamer als der ursprüngliche Code sein. Einige Beispiele werden wir daher mit und ohne JIT testen, um dieses Problem aufzuzeigen.
Eigener Profiler
Bevor Sie Ihre Javaanwendung optimieren können müssen Sie erst einmal wissen, wo das Performanceleck liegt. Der Einsatz von Profilertools ist eine gute Möglichkeit. Eine andere Möglichkeit ist die Ausführungsgeschwindigkeit selbst zu messen.
Die können Sie gut umsetzen, indem Sie zwischen den Anweisungen die Zeit ausgeben. Mit der Operation System.currentTimeMillis() können Sie dies schnell durchführen. Hierbei machen Sie Ihr eigenes Profiling. Der bedeutende Vorteil ist, dass keine weiteren Anwendungen (Profilertools) den Prozessor in Beschlag nehmen. Somit sind reale Zeitmessungen auf dem System möglich. Sie können jedoch nicht messen, wo innerhalb einer Fremdmethode eventuell Performanceprobleme liegen. Auch die Aufrufreihenfolge von Methoden können Sie nicht nachvollziehen.
Da diese beiden Punkte jedoch eine nicht zu unterschätzende Relevanz haben kann, ist der Einsatz eines Profilertools durchaus sinnvoll. Auch hier lässt uns Sun Microsystem nicht im Stich. Die JVM beinhaltet bereits einen Profiler, welchen Sie nur zu aktivieren brauchen.
| JVM Version | Aufruf / Parameter |
| JVM 1.1.x final | java -prof |
| JVM 1.2.x final | java -Xrunhprof |
| JVM 1.3.x final | java -Xrunhprof |
Tabelle 3 - Aufruf des Profiler der JVM
Die Standardausgabedatei heißt „java.prof“. Diese ist jedoch sehr kryptisch und in reiner Textform. Kommerzielle Profiler stellen die Ausgabe meist grafisch dar und erleichtern somit die Analyse. Glücklicherweise haben sich bereits einige Entwickler an die Arbeit gemacht und Tools umgesetzt, die unsere Profiledatei auch ohne Kryptografen lesbar machen. Sie finden diese Tools „HyperProf“ und „ProfileViewer“ im Internet.
Java Virtuelle Machine
Das Wissen über die Besonderheiten der JVM ist Grundlage für viele Optimierungsmöglichkeiten. Daher sollten Sie als Programmierer diesen Abschnitt genauer betrachten.
Zugriffsgeschwindigkeit auf Typen
Die JVM ist ein 32 Bit System. Aus diesem Grund sind Zugriffe auf Variablen mit einer Breite von 32 Bit am schnellsten. Somit ist der Zugriff auf Referenzen und int Variablen besonders schnell. float Variablen, sind Fliesskommazahlen und können nicht ganz so schnell verarbeitet werden. Die primitiven Datentypen unterscheidet man auch in Datentypen erster Klasse und Datentypen zweiter Klasse. Datentypen erster Klasse sind int, long, float und double. Für diese Datentypen liegt ein kompletter Satz an arithmetischen Funktionen vor, so dass Berechnung relativ zügig vonstatten gehen. Die Datentypen zweiter Klasse boolean, byte, short und char hingegen haben keine arithmetische Funktionen. Für Berechnungen werden diese innerhalb der JVM in den int Typ gecastet und nach Abschluss zurück umgewandelt. Dies führt zu erheblichen Zeitverzögerungen. (siehe auch Variablen / Datentypen und Operatoren).
Rechengeschwindigkeit für Gleitpunktdatentypen
float und double sind gemäß der Java Spezifikation Datentypen mit einer Genauigkeit von 32 Bit bzw. 64 Bit. In der IEEE 754 werden jedoch auch Gleitpunktdatentypen mit Genauigkeiten von mindestens 43 Bit bzw. 79 Bit vorgesehen. Seit dem JDK 1.2 können nunmehr Java Virtual Machines diese Genauigkeiten zur Beschleunigung der Rechenoperationen mit den beiden Datentypen nutzen. Sofern die Hardware höhere Genauigkeiten unterstützt unterbleibt das Umrechnen auf die Genauigkeit der Datentypen während der Rechenoperationen. Dies führt zu einer Geschwindigkeitserhöhung bei entsprechenden Berechnungen.
Die interne Darstellung der Datentypen verbleibt jedoch bei den 32 Bit für float bzw. 64 Bit für double. Die Änderung der Java Spezifikation hat außerdem dazu geführt, das in Abhängigkeit von der verwendeten Hardware und der Java Virtual Machine unterschiedliche Ergebnisse auftreten können. Um den Entwicklern eine Möglichkeit zu geben dies zu unterbinden wurde das Schlüsselwort strictfp eingeführt. Dieses kann auf Klassen und Methodendeklarationen angewendet werden und zwingt die JVM die alten Berechnungsverfahren anzuwenden - mit dem entsprechenden Geschwindigkeitsverlust.
Stackorientierter Prozessor der JVM
Der Prozessore der JVM ist stackorientiert und hat eine Breite von 32 Bit. Parameter und Rückgabewert von Methoden werden jeweils über dieses Stack gereicht. Lokale Variablen einer Methode können Sie dabei mit den Registern der CPU vergleichen. Dies hat unter anderem zur Folge, dass die Erzeugung eines neuen Threads stets auch zur Erzeugung eines eigenen Stacks für diesen führt (Java Stack).
Sobald Sie eine Methode aufrufen, wird für ein neuer Datensatz reserviert, in welchem der aktuelle Zustand gesichert wird (Methodenoverhead). Methoden können dabei Ihre eigene lokalen Variablen haben. Für den Zugriff auf die ersten 4 Slots (128 Bit) des Stack haben Ihre Methoden einen speziellen Bytecode. Daher kann durch gezielte Belegung der Slots die Geschwindigkeit innerhalb einer JVM (Bytecode Interpreter) erhöht werden. Bei den moderneren JIT und HotSpot Compilern führt dies jedoch nicht zu Gewinnen. Slots werden nach folgendem Schema belegt. Wenn es eine Objektmethode ist, wird der erste Slot mit einer Referenz auf das Objekt belegt (32 Bit). Werden Parameter übergeben so belegen diese die folgenden Slots. Danach belegen die lokalen Variablen in der Reihe Ihres Auftretens den Slot. Durch eine gezielte Deklaration der lokalen Variablen können Sie also weitere Performancegewinne erzielen. Dies bietet sich z.B. bei den Zählvariablen größerer Schleifen an. Beachten Sie: Ein Array wird immer mit der Referenz (32 Bit) übergeben, wobei sich nur die Zugriffsgeschwindigkeit auf das Array, nicht dessen Inhalt, erhöht. Die Typen double und long benötigen 2 Slots.
Eine weitere Steigerung ist in Verbindung mit dem Memory Access Pattern möglich.
JIT contra Interpreter
JIT und Hot Spot Compiler haben andere Ansprüche als ein Bytecode Interpreter an Sie, wenn es um die Optimierung der Performance geht. Für Bytecode Interpreter kann z.B. das gezielte Belegen der Slotvariablen Performancegewinne bringen. Auch der Zugriff auf die Variablen ist bei Bytecode Interpreter anders zu bewerten.
Variablen / Datentypen und Operatoren
Operatoren
Die richtige Verwendung der Operatoren von Java kann Ihre Anwendung beschleunigen. Wichtig ist jedoch, dass Sie die Semantik der verschiedenen Operatoren kennen. So kann das Shiften in einigen Fällen die Division bzw. Multiplikation ersetzten und beschleunigen - jedoch nicht immer. Einige Grundsätze können Sie jedoch beachten.
Die Verwendung von verbundenen Zuweisungen kann durch den Compiler effizienter umgesetzt werden. Somit sollten Sie besser x++; als x+=1; als x=x+1; schreiben. Einige neuere Compiler erkennen jedoch bereits derartigen Quelltext und können diesen ebenfalls optimieren.
Sie sollten nie die Typinformationen verlieren. Die Operationen instanceof und das Casten mittels (type) sind nicht sehr performant und überflüssig, wenn Sie den Typ des Objektes kennen.
Die Operatoren:
„++“, „--“, „+“, „-“, „~“, „!“, „(type)“, „*“, „/“, „%“, „<<“, „>>“, „>>>“, „<“, „<=“, „>“, „>=“, „instanceof“, „==“, „!=“, „&“, „^“, „|“, „&&“, „||“, „?:“, „=“, „*=“, „/=“, „%=“, „+=“, „-=“, „<<=“, „>>=“, „>>>=“, „&=“, „^=“, „|=“, „new“
Variablen bzw. Attribute
Die Initalisierung von Variablen ist in Java nicht stets notwendig. Klassen und Instanzvariablen werden automatisch initalisiert. Referenzen bekommen hierbei den Wert null; primitive Datentypen bekommen den Wert 0. Auch die Inhalte eines Array werden automatisch initalisiert, sofern das Array bereits eine gültige Referenz ungleich null aufweist. In Abhängigkeit vom Java Compiler kann unnötiger Bytecode vermieden werden, indem Sie auf die Initalisierung mit den Standardwerten verzichten.
Falls Sie Optimierung um jeden Preis möchten, können Sie durch den direkten Attributzugriff weitere Geschwindigkeitsvorteile erreichen. Dies ist natürlich nur bedingt möglich. Bei Javabeans können Sie auf die Zugriffsmethoden nicht verzichten. Zudem ist Ihre Anwendung nicht mehr Objektorientiert und die Wartung einer solchen Anwendung auf Dauer vermutlich zum Scheitern verurteilt. Zum Testen bietet sich hier eine Schleife an. Die Geschwindigkeit des Attributzugriffs kann dabei etwa auf das Doppelte erhöht werden.
Auch die Sichtbarkeit von Variablen sollten Sie für einen effizienten Zugriff beachten.
Sichtbarkeit
Die Geschwindigkeitsgewinne / -verluste je nach Sichtbarkeit unterscheiden sich sehr je nach eingesetzter JVM. Daher können nur sehr wenige allgemeingültige Aussagen gemacht werden. Ein Quelltext zum Testen der Zugriffsgeschwindigkeiten finden Sie im Anhang. Wissen sollten Sie jedoch, das Methodenvariablen stets sehr schnell behandelt werden können. Aus diesem Grund existiert das Memory Access Pattern.
Memory Access Pattern
Das Memory Access Pattern wird häufig eingesetzt um, die Zugriffsgeschwindigkeit auf Variablen zu erhöhen. Es wird dabei nur innerhalb einer Methode verwendet. Ziel ist es den Wert einer Variablen innerhalb einer Methode schnell zu verändern und diesen nach Abschluss nach außen bereitzustellen. Besonders bei sehr zeitaufwendigen Operationen mit langsameren Variablentypen kann dies Geschwindigkeitsvorteile in Ihrer Anwendung bringen. Beachten Sie jedoch, dass gerade bei Multithreading der Zugriff ggf. synchronisiert werden muss.
package bastie.performance.zugriffaufvariablen;
public class MemoryAccessPattern {
private IntegerWrapper iw = new IntegerWrapper();
private final int durchlauf = 10000000;
public MemoryAccessPattern() {
}
public final void normalZugriff(){
System.out.println("Normaler Zugriff");
long start;
start = System.currentTimeMillis();
for (int i = 0; i < durchlauf; i++){
iw.setValue(iw.getValue()+1);
}
System.out.println("Zeit = "+(System.currentTimeMillis()-start)+"ms\n\r\n\rvalue = "+this.iw.getValue());
}
public final void mapZugriff(){
System.out.println("MemoryAccessPattern Zugriff");
long start;
start = System.currentTimeMillis();
int j = iw.getValue();
for (int i = 0; i < durchlauf; i++){
j++;
}
this.iw.setValue(j);
System.out.println("Zeit = "+(System.currentTimeMillis()-start)+"ms\n\r\n\rvalue = "+this.iw.getValue());
}
public final void syncmapZugriff(){
System.out.println("Synchronisierter MemoryAccessPattern Zugriff");
long start;
start = System.currentTimeMillis();
synchronized (iw){
int j = iw.getValue();
for (int i = 0; i < durchlauf; i++){
j++;
}
iw.setValue(j);
}
System.out.println("Zeit = "+(System.currentTimeMillis()-start)+"ms\n\r\n\rvalue = "+this.iw.getValue());
}
public static void main (String[] args){
MemoryAccessPattern map = new MemoryAccessPattern();
map.normalZugriff();
map.mapZugriff();
map.syncmapZugriff();
}
}
class IntegerWrapper {
private int value;
public int getValue() {
return value;
}
public void setValue(int newValue) {
value = newValue;
}
}
Das Verhältnis von Normalen - zu Memory Access Pattern - zu synchronisierten Memory Access Pattern Zugriff beträgt je nach System etwa 920 : 90 : 150 (JDK 1.3 Client HotSpot) bzw. 5650 : 1800 : 1830 (JDK 1.3 Interpreter Modus). Eine weitere sinnvolle Anwendung besteht darin primitive Datentypen in int zu casten, in der Methode mit diesem schnellen Datentyp zu arbeiten und dann erst das Rückcasten vorzunehmen.
Zeichenketten
Für die Verwaltung von Zeichenketten bieten sich grds. drei Möglichkeiten an: die Klasse String, die Klasse Stringbuffer und ein char Array. Die Klasse String ist final und besitzt nur Lesemethoden. Daher ist für die Arbeit mit veränderlichen Zeichenketten grundsätzlich die Klasse Stringbuffer zu bevorzugen. Diese verwaltet intern ein char Array, auf welchem sie die Lese- und Schreibmethoden ausführt. Die schnellste Möglichkeit ist schließlich das direkte arbeiten mit einem char Array ohne einen Stringbuffer als Wrapper zu verwenden. Die Arbeit mit der Klasse Stringbuffer ist jedoch wesentlich komfortabler als direkt auf ein char Array zuzugreifen.
Sie werden sicher schon gehört haben, dass für das Verketten von Zeichenketten die Nutzung der Klasse Stringbuffer schnelleren Bytecode erzeugt. Dies ist grundsätzlich richtig, sofern Sie mehr als zwei Zeichenketten verketten wollen. Die Klasse Stringbuffer können Sie dabei jedoch weiter optimieren, indem Sie die synchronisierten Methoden ersetzen.
Primitive Datentypen
Die JVM ist ein 32 Bit System. Aus diesem Grund sind Zugriffe auf Variablen mit einer Breite von 32 Bit am schnellsten. Somit ist der Zugriff auf Referenzen und int Variablen besonders schnell. float Variablen, sind Fliesskommazahlen und können nicht ganz so schnell verarbeitet werden. Die primitiven Datentypen unterscheidet man auch in Datentypen erster Klasse und Datentypen zweiter Klasse. Datentypen erster Klasse sind int, long, float und double. Für diese Datentypen liegt ein kompletter Satz an arithmetischen Funktionen vor, so dass Berechnungen relativ zügig vonstatten gehen. Die Datentypen zweiter Klasse boolean, byte, short und char hingegen haben keine arithmetische Funktionen. Für Berechnungen werden diese innerhalb der JVM in den int Typ gecastet und nach Abschluss zurück umgewandelt. Dies führt zu erheblichen Zeitverzögerungen.
Zahlensysteme
Die Umwandlung von einem Zahlensystem in ein anderes wird mit Hilfe der Klasse Integerin Java bereits unterstützt. Hierbei stellt die Klasse zum einem die Möglichkeit mit Hilfe der Methode toString(wert, basis), sowie spezialisierte Methoden wie toHexString(wert) zur Verfügung. Die spezialisierten Methoden bieten Ihnen dabei einen Geschwindigkeitsvorteil, da hier das schnellere Shiften bei einer Basis verwendet wird, welche selbst auf der Basis 2 berechnet werden kann. Somit benötigt toHexString (JDK 1.3) etwa 889 Zeiteinheiten zu 1.362 Zeiteinheiten bei toString zur Basis 16. Die Umwandlung eines primitiven Datentyp ist grundsätzlich stets mit den spezialisierten Methoden der Wrapperklassen vorzunehmen. So ist die Umwandlung einer Ganzzahl vom Typ int mit der statischen Methode Integer.toString() etwa doppelt so schnell wie ‚""+int‘.
Sammlungen - Container für Datentypen
Sammlungen sind einige der Klassen / Objekte, welche mit am häufigsten Verwendung finden.
Sammlungen sollten Sie nach Möglichkeit immer auf Objekt- bzw. Klassenebene deklarieren und definieren. Wenn Sie eine Sammlung lediglich innerhalb einer Methode deklarieren / definieren, so wird bei jedem Methodenaufruf eine neue Initialisierung dieser vorgenommen.
Arrays
Ein Array hat gegenüber den Sammlungen des Collection Frameworks bestimmte Vor- und Nachteile. Arrays behalten die Typinformationen. Dadurch entfällt in Ihrer Anwendung das unperformante casten der Typen. Dies ist jedoch gleichzeitig eine Einschränkung. Ihr Array kann nur Objekte eines Typs aufnehmen. Außerdem muss die maximale Anzahl der Elemente Ihres Array bekannt sein.
Ob Sie ein Array verwenden können, um die Performance Ihrer Anwendung zu erhöhen hängt daher von verschiedenen Voraussetzungen ab. Wenn Sie die voraussichtliche größtmögliche Anzahl der Elemente kennen oder die Anzahl der Elemente keinen großen Schwankungen unterliegt ist ein Array performanter als eine andere Sammlung. Benötigen Sie eine Sammlung für Objekte verschiedener Typen, müssen Sie prüfen, ob es einen Typ (Superklasse, Interface) gibt, welcher allen Objekten gemeinsam ist. In diesen Fällen ist ein Array meist die performantere Alternative zu anderen Sammlungen. Ziel sollte es stets sein, dass alle (häufig) benötigten Informationen ohne einen Cast erreichbar bleiben.
Gerade wenn Sie häufig mit Arrays arbeiten sollten Sie sich genügend Zeit für die Optimierung dieser nehmen. Die Initialisierung eines Array kostet nicht nur Zeit, sondern vergrößert auch den Bytecode Ihrer Anwendung. Dies führt neben dem erhöhten Speicherplatzbedarf zur Laufzeit ggf. auch zu einer vermehrten Netzwerkbelastungen.
Eine Möglichkeit, wie Sie diesem Problem zu Leibe rücken können, ist das optionale Nachladen der benötigten Daten. Hier kann der Bytecode erheblich verringert werden. Auch die Netzwerklast sinkt, da Sie nur wirklich benötigte Daten über das Netz versenden müssen. Bei der Erstellung von Applets bietet sich diese Vorgehensweise besonders an, da die Bandbreite meist eingeschränkt und nicht vorhersehbar ist. Beachten Sie dabei, dass diese Daten nicht in der selben jar Datei liegen, wie Ihre Anwendung.
Ein anderer Ansatzpunkt, der als wesentliches Ziel nicht die Verkleinerung des Bytecode, sondern die Erhöhung der Ausführungsgeschwindigkeit zum Ziel hat, liegt in der Einschränkung der Sichtbarkeit. Wie jedes Objekt ist es stets sinnvoll ein Array als private final vorliegen zu haben. Durch die Optimierungen, die der Compiler somit an Ihrer Anwendung vornehmen kann, ist es möglich eine höhere Ausführungsgeschwindigkeit zu erreichen.
Arrays kopieren
Eine häufige Anwendung ist auch das Kopieren von Arrays. Dafür gibt es grundsätzlich drei verschiedene Möglichkeiten. Das Kopieren innerhalb einer Schleife. Das Klonen eines Arrays und das Verwenden der Methode System.arraycopy(). Die letzte Möglichkeit hat den Vorteil, dass es sich um eine nativ implementierte Methode handelt, welche für diese Aufgabe entsprechend optimiert ist. Sie sollten grds. diese Variante bevorzugen, da Sie sowohl bei Bytecode Interpretern als auch bei JIT- und HotSpot Compilern die schnellsten Ergebnisse liefert. Bei JIT- bzw. HotSpot Compilern ist der Unterschied zum Kopieren innerhalb einer Schleife jedoch nicht mehr so hoch.
// Array kopieren
System.arraycopy(array,0,klon,0,10);
// Array klonen
int [] klon = (int[]) array.clone();
Arrays durchlaufen
Das Durchlaufen von Arrays ist ebenfalls eine häufig auftretende Verwendung. Gerade bei großen Datenmengen und somit großen Arrays macht sich jedoch der Schleifenoverhead bemerkbar. Der Schleifenoverhead entsteht dabei u.a. durch die Gültigkeitsprüfungen (siehe auch Schleifen). Sie haben jedoch eine Alternative. Anstatt bei jedem Schleifendurchlauf zu prüfen, ob das Ende des Arrays erreicht wurde lassen Sie Ihre Anwendung bewusst auf einen Fehler laufen. Die erzeugte ArrayIndexOutOfBoundsException fangen Sie dann gekonnt ab. Gerade bei Bytecode Interpretern können Sie hier nicht zu unterschätzende Geschwindigkeitsvorteile erringen.
Hashtable
Die Hashtable ist eine schnelle Datenstruktur, deren Geschwindigkeit u.a. von Ihrem Füllfaktor abhängt. Bei Aufruf des Konstruktors können Sie, durch Angabe eines eigenen Füllfaktors die Geschwindigkeit und den Platzbedarf zur Laufzeit bestimmen. Der Standardwert unter Java ist 75% und sollte für eine schnelle Anwendung nicht überschritten werden. Wird der Füllfaktor einer Hashtable überschritten so findet ein rehashing statt. Dabei wird eine neue (größere) Hashtable angelegt. Die alte Hashtable wird in die neue überführt, wobei alle Hashcodes neu berechnet werden. Eine schnelle Hashtable setzt somit voraus, dass ein rehashing nur in begrenztem Umfang erfolgt.
Die Identifizierung der einzelnen Objekte in einer Hashtable erfolgt über den Hashcode. Daher sollten Sie bei der Wahl des Schlüsseltyps vorsichtig sein. Während bei einer kleinen Hashtable der Schlüsseltyp nur geringen Einfluss auf die Performance hat, sollten Sie bei einer großen Hashtable als Schlüsseltyp nicht Objekte der Klasse String verwenden. Hier bieten sich eher Objekte der Klasse Integer an, da deren Hashcode schneller berechnet werden können.
Die Hashtable ist auch nach der Anpassung an das Collection-Framwork weiterhin zu einem großen Teil synchronisiert. U.a. gilt dies auch für die Methode clear(). Daher sollten Sie, wenn Sie einen Objektpool mit einer Hashtable aufbauen, diese Methode nicht verwenden. Hier bietet es sich statt dessen, eine neue Hashtable zu definieren.
Die IntHashtable
Das sich die Sammlungen nicht für primitive Datentypen eignen, liegt daran, dass eine Sammlung nur Objekte aufnehmen kann. Die Entwickler von Java wollten sich jedoch offenbar nicht dieser Einschränkung unterwerfen und haben sich daher eine Hashtable für int Werte geschrieben.
Diese Hashtabe ist versteckt im Paket java.text. Da Sie netterweise final deklariert ist, ist ein Aufruf leider nicht möglich. Hier hilft nur „Copy & Paste“. Die Verwendung dieser Klasse ist jedoch wesentlich performanter als das Verpacken von int Werten in Integer. In unseren Beispiel zur Berechnung von Primzahlen haben wir diese z.B. verwendet.
Die HashMap
Mit dem Collection Framework wurde u.a. auch die Klasse HashMap eingeführt. Sie kann als Ersatz für eine Hashtable verwendet werden, sofern keine Synchronisation benötigt wird. Durch die fehlende Synchronisation ist der häufige Zugriff auf eine HashMap bedeutend schneller. Auch bei der Hashmap ist jedoch wie bei der Hashtable die Wahl des richtigen Schlüsseltyps wichtig. Zudem ist die Klasse HashMap auch noch flexibler als Hashtable.
Der Vector, der Stack, die ArrayList und die LinkedList
Die Klasse Vector ist eine der flexibelsten Strukturen der Sammlungen. Sie ist bereits seit dem JDK 1.0 vorhanden und ist daher auch weiterhin synchronisiert. Auch hier bietet sich daher eine Prüfung an, ob einer derartige Synchronisation benötigt wird. Sofern dies nicht der Fall ist, verwenden Sie besser die Klassen ArrayList oder LinkedList. Sofern Sie auf Java 1 angewiesen sind, müssen Sie zwangsläufig sich eine eigene Klasse basteln. Da die Klasse Stack eine Subklasse von Vector ist, gelten diese Ausführungen ebenfalls.
Die Klasse ArrayList ist als nicht synchronisierter Ersatz für die Klasse Vector mit dem Collection Framework aufgetaucht. Sie ist, wie auch die LinkedList nicht synchronisiert, so dass der Zugriff auf Elemente dieser Sammlungen schneller ist.
Synchronisierte Sammlungen
Bis zum JDK 1.2 hatten Sie keine große Auswahl. Seitdem hat sich jedoch eine Menge getan. Es wurde der Typ java.util.Collection in Form eines Interfaces eingeführt, auf welchem alle aktuellen Sammlungen beruhen. Auch die bisherigen Typen, wie Vector wurden entsprechend angepasst. Bis zum JDK 1.2 bedeutet die Verwendung von Sammlungen immer auch Synchronisation, welche Sie nur durch Erstellung eigener Klassen verhindern konnten. Seit dem JDK 1.2 ist jede Sammlung, bis auf Vector und Hashtable nicht synchronisiert.
Es ist aber für viele Aufgaben durchaus sinnvoll bzw. nötig mit synchronisierten Sammlungen zu arbeiten. Dies stellt jedoch keine großen Anforderungen an die Implementierung dar. Mit Hilfe der Fabrikmethoden der Klasse java.util.Collections können Sie synchronisierte Sammlungen erzeugen.
// Beispiel synchronisieren einer TreeMap
TreeMap treeMap;
treeMap = (TreeMap)Collections.
synchronizedSortedMap(new TreeMap());
Beim Aufruf einer Methode wird die Synchronisation durch den von Ihnen soeben erzeugten Wrapper bereit gestellt. Dieser leitet daraufhin den Aufruf an Ihre ursprüngliche Sammlung weiter. Für eine nicht synchronisierte Version eines Vector können Sie die Klasse ArrayList verwenden. Die Klasse HashMap können Sie statt der synchronisierten Hashtable verwenden.
| nicht synchronisiert | synchronisiert |
| HashSet | |
| TreeSet | |
| ArrayList | Vector |
| LinkedList | Stack |
| HashMap | Hashtable |
| WeakHashMap | |
| TreeMap | |
Sammlungen eignen sich grundsätzlich nur für Objekte. Sollten Sie eine große Anzahl von primitiven Datentypen sichern wollen ist ein Array die bessere Alternative, da das Verpacken der primitiven Datentypen in Objekte zu einem enormen Overhead führt.
Methoden
Zu jeder nicht abstrakten Klasse gehören auch Methoden und im Sinne der Objektorientierung delegieren Methoden ihre Aufgaben an andere Methoden. Dies ist sinnvoll, wünschenswert und gut. Es kann jedoch zu einer Geschwindigkeitsfalle werden.
Ein Problem ist das verhindern von Doppelaufrufen. Da die Java Entwickler den Quelltext des JDK offengelegt haben, sollten Sie einen Blick in diesen öfter riskieren. Schauen Sie sich die Implementation von Methoden an, um unnötige Aufrufe zu vermeiden. Ein weiterer wichtige Punkt sind die benötigten Variablen. Der Zugriff auf diese sollte so schnell wie möglich sein. Hierzu sollten Sie ggf. vom Memory Access Pattern gebrauch machen. Ziel dieses ist es den Wert einer Variablen innerhalb einer Methode schnell zu verändern und diesen nach Abschluss nach außen bereitzustellen. Besonders bei sehr zeitaufwendigen Operationen mit langsameren Variablentypen kann dies Geschwindigkeitsvorteile in Ihrer Anwendung bringen. Beachten Sie jedoch, dass gerade bei Multithreading der Zugriff ggf. synchronisiert werden muss.
Es gibt zwei Arten von Methoden - Methoden die statisch aufgelöste werden können und solche, bei denen dies nicht möglich ist. Methoden die statisch aufgelöst werden können sind als static, final oder private deklariert sind bzw. Konstruktoren. Die anderen können erst zur Laufzeit aufgelöst werden, so dass der Compiler bei der Bytecodeerstellung keine Optimierungen vornehmen kann. Auch die Sichtbarkeit von Methoden beeinflussen deren Ausführungsgeschwindigkeit. Für die Geschwindigkeit kann daher grob von folgender Hierarchie ausgegangen werden:
static => private => final => protected => public Methoden bzw.
static => final => instance => interface => synchronisierte Methoden.
Häufig wird empfohlen Methoden, welche nicht überschrieben werden als final zu deklarieren. In der Implementierung sollte dies nicht mehr zur Debatte stehen; dies ist Aufgabe des Designs.
Methodenaufrufe optimieren
Inlining
Als quasi-goldene Regel gilt: „Nur eine nicht vorhandene Methode, ist eine gute Methode“. Umgesetzt heißt dies Inlining. Jede Methode hat einen Overhead, der u.a. durch Initalisierung ihres Methoden-Stack entsteht. JIT- und HotSpot-Compiler können die Auswirkungen zwar minimieren, jedoch noch nicht völlig wettmachen. Das Inlining, bedeutet nichts anderes, als den Inhalt einer Methode, an den Platz ihres Aufrufes zu kopieren. Bei statisch auflösbaren Methoden kann der Javacompiler „javac“ dies bereits übernehmen. Dies hat den Vorteil, dass sowohl Design als auch Implementierung ‚sauber‘ bleiben und trotzdem eine höhere Ausführungsgeschwindigkeit erreicht werden kann. Mit dem Schalter „-o“ wird der Optimierungsmodus des Compilers eingeschaltet. Kapselmethoden können nicht inline gesetzt werden. Sofern Sie die Geschwindigkeit weiter erhöhen wollen, können Sie auch manuelles Inlining vornehmen. Gegen Inlining spricht jedoch, dass längerer Bytecode erzeugt wird.
Überladene Methoden nutzen
Mit der Möglichkeit überladene Methoden zu erstellen haben wir eine mächtiges Mittel zur Verfügung, um ein Paket für einen Programmierer gut nutzbar zu machen. Dies zusammen mit der Möglichkeit Aufgaben zu delegieren macht u.a. eine gute Klassenbibliothek aus. Gerade dieses Delegieren zu umgehen, kann jedoch die Geschwindigkeit erhöhen. Die Implementation der Methode Exception.printStackTrace() sieht beispielsweise so aus:
public void printStackTrace() {
synchronized (System.err) {
System.err.println(this);
printStackTrace0(System.err);
}
Wenn Sie sich den Quellcode näher betrachten stellen Sie evtl. fest, dass Sie auch selbst den Aufruf der Methode Exception.printStackTrace(); mit einem Parameter PrintStream System.err vornehmen könnten und auch synchronisieren von System.err stellt keine Anforderung an Sie dar. Testen Sie selbst bei welchen Methoden dies auch sinnvoll sein kann. Falls Sie nur in einem Thread arbeiten, werden Sie die Synchronisierung nicht einmal mehr umsetzen. Dies führt zu einem weiteren Punkt:
Methoden überschreiben / Eigene Methoden nutzen
Wir befassen uns jetzt mit einem weiteren elementaren Punkt der Objektorientierung der Polymorphie. Natürlich will ich jetzt nicht auf das gesamte OO Konzept eingehen, was hinter diesem Begriff steht, Sie können dieses Prinzip jedoch gut für Ihre Performanceoptimierungen verwenden. Polymorphie bedeutet letztendlich nichts anderes, als dass, wenn Sie eine ererbte Methode aufrufen, zuerst das Objekt nach der entsprechenden Methode durchsucht wird, dann die Superklasse, dann die SuperSuperklasse usw. Dies ist ein sehr schönes und brauchbares Konzept hat jedoch auch seine Nachteile, so dass bestimmte Methoden stets überschrieben werden sollten. Dies hat nicht nur Performancegründe sondern ist vielfach einfach sinnvoll. Ein besonders verständliches Beispiel lässt sich an der Methode Object.equals(Object); zeigen. So kann bereits bei einer kleinen Vererbungsstruktur ein Vergleich optimiert werden:
class Frau extends Mensch{
public boolean equals(Object o) {
if (o instanceof Frau){
super.equals(o);
}
return false;
}
public void gebähre(){
}
// hier kommt noch mehr
}
Die andere Möglichkeit ist das Verwenden eigener Methoden. Die Methoden der Java Klassenbibliotheken sollen jeden denkbaren Fall abdecken. Dies führt zu vielen Prüfungen, welche in Ihrer Anwendung evtl. nicht oder nur selten benötigt werden. Hier bietet es sich an eine eigene Methode zu schreiben, welche diese Aufgabe erledigt. Dies ist ebenfalls sehr sinnvoll bei synchronisierten Methoden. Sollte die Anzahl der Methoden sehr hoch werden, so bietet es sich wahrscheinlich sogar an, eine eigene spezialisierte Klasse zu schreiben. Dies führt zugleich zu einer flacheren Vererbungshierarchie, wodurch die Performance weiter erhöht wird.
Synchronisierte Methoden
Sie sollten synchronisierte Methoden vermeiden. Selbst wenn Sie mit nur einem Thread arbeiten sind synchronisierte Methoden langsamer. Wenn Sie eine Synchronisation erzeugen, erstellt die JVM zuerst einen Monitor für diesen Teil. Will ein Thread nun den Programmteil ausführen so muss er zuerst sich beim Monitors anmelden (und ggf. warten). Bei jedem Aufruf / Verlassen eines solchen Programmteils wird der Monitor benachrichtigt, was entsprechende Verzögerungen mit sich bringt.
Objekte
Objekte sind der Hauptbestandteil Ihrer Anwendung, jeder OO Anwendung. Daher wollen wir nun einige der Performancemöglichkeiten in Zusammenhang mit Objekten betrachten. Wenn es Ihnen im Augenblick um das Sichern von Objekten geht, sollten Sie gleich in den Abschnitt Sicherung und Wiederherstellung von Objekten im Teil Ein- und Ausgabe gehen.
Erzeugung von Objekten
Java verfügt inzwischen über eine Unmenge von Möglichkeiten Objekte zu erzeugen. Zu diesen Möglichkeiten zählen der
- new Operator
- Object.getClass().newInstance()
- Class.forName(‚package.Class‘).newInstance()
- object.clone()
- mittels Reflection
- die Wiederherstellung von gesicherten Objekten.
Außerdem gibt es noch die Möglichkeit mit ClassLoader Klassen als Bytekette zu laden.
Der „new” Operator ist der gebräuchlichste und schnellste dieser Möglichkeiten. Da Sie mit diesem die Konstruktoren aufrufen lohnt es sich diese genauer zu betrachten. Konstruktoren sind besondere Methoden, welche nur von einem Thread gleichzeitig aufgerufen werden können. Die Instanztierung eines Objekt ist keine performante Sache. Auch die JIT Compiler konnten diesen Flaschenhals bisher nicht beseitigen. Es liegt an Ihnen dies durch geeignete Konstrukte auszugleichen. Wenn Sie eine Abstraktionsebene tiefer in Ihrer Klassenbibliothek gehen, so bedeutet dies immer auch den Aufruf von einem oder mehreren weiteren Konstruktoren, daher sind flache Vererbungshierarchien performanter. Allerdings ruft nicht nur der „new” Operator einen Konstruktor auf, sondern auch das Wiederherstellen über die Schnittstelle Externalizable führt zum Aufruf des Standardkonstruktor. Es ist daher sinnvoll Objekte wieder zu verwenden, statt neu zu erstellen (siehe Wiederverwendung von Objekten).
Einen wirklich performanten, schnellen Konstruktor zu erstellen führt zwangsläufig wieder zur Kollision mit dem Design, da Sie hier die Delegation einschränkend müssen. Wenn Sie beispielsweise ein 100 Jlabel Objekte erzeugen, können Sie durch verwenden des überladenen Konstruktors (übergeben Sie „Text“, null, JLabel.LEFT) schon einen Geschwindigkeitsgewinn zwischen 230% (JIT Compiler) bis 830% (Bytecode Interpreter) zum Aufruf des Standardkonstruktors mit „Text“ verbuchen.
Um die Erstellung eines Objektes zu beschleunigen sollten Sie auf unnötiges Initalisieren von Variablen verzichten. Objekt- und Klassenvariablen erhalten als Referenz grds. den Wert null, während primitive Datentypen mit 0 initalisiert werden.
Innere Klassen
Inner Klassen sind langsamer als andere Klassen. Hier kann Sie die Erzeugung eines Objektes bei Ausführung mit einem Bytecode Interpreter durchaus die doppelte Zeit kosten. Bei JIT- und HotSpot Compilern liegt hier jedoch keine große diese Differenz mehr vor. Um für Bytecode Interpreter gerüstet zu sein, bietet es sich jedoch ggf. an, Klassen mit einer auf das Paket begrenzten Sichtbarkeit zu erstellen.
Ein weiterer Punkt ist die Größe des Bytecodes. Innere Klassen führen zu wesentlich mehr Bytecode als die vergleichbare Variante einer Klasse mit der Sichtbarkeit auf Paketebene.
class WoIC {
MyOuter outer;
}
class WiIC {
class MyInner {
}
}
class MyOuter {
}
Der Unterschied für diese Klassen liegt beim dem normalen Kompiliervorgang bei 216 Bytes.
Dynamisches Nachladen von Klassen
Das gezielte Nachladen von Klassen kann die Performance weiter anheben. Mittels Class.forName() können Sie zu einem beliebigen Zeitpunkt Klassen in Ihre Anwendung laden. Dies kann in einem Low-Priority-Thread sehr hilfreich sein, um im Hintergrund bereits weitere Anwendungsteile zu initialisieren. Auch in Applets können Sie Klassen laden. Somit ist es Ihnen möglich, Objekte erst dann zu laden, wenn Sie diese benötigen. Gerade für eine Verringerung der Netzwerklast bzw. dem schnellen starten von Applets ein gutes Konstrukt.
Konstante Klassen
Eine Eigenschaft einiger Standardklassen von Java ist deren Deklaration als final. Dies sind u.a. die Klasse String sowie die Wrapperklassen für die primitiven Datentypen Boolean, Byte, Character, Double, Float, Integer und Long. Dieses Konstrukt kann jedoch zu Performanceeinbüssen führen. Bei der Klasse String wird daher meist die Verwendung der Klasse StringBuffer zum Verketten von Zeichenketten vorgeschlagen. Dieses Konstrukt ist jedoch nur dann schneller, wenn es sich um mehr als zwei Zeichenketten handelt. Bei lediglich zwei Zeichenketten ist die Verwendung des ‚+‘-Operators schneller als die append Methode der Klasse StringBuffer. Auch die Wrapperklassen können zu Performanceeinbüssen führen. Dies ist insbesondere mit den grafischen Swing Komponenten zu beachten, da Sie für jeden Wert auch jeweils ein neues Objekt erstellen müssen.
Sicherung von Objekten
Das Sichern und Wiederherstellen wird ausführlich im Abschnitt Ein- und Ausgabe unter „Sicherung und Wiederherstellung von Objekten“ behandelt, da die Sicherung stets auch ein Problem der Ein- und Ausgabe ist.
Verwerfen von Objekten
Ihre Referenzen sollten Sie erst dann freigeben, wenn Sie diese nicht mehr benötigen. Neben den Performancekosten für das Anlegen eines neuen Objektes kommt ansonsten auch noch die für die GarbageCollection dazu. Das gezielte Verwerfen (object = null;) von nicht mehr benötigten Objekten kann die Performance erhöhen. Dies liegt an dem Verhalten der GarbageCollection. Diese überprüft alle Objekte, die sich im Arbeitsspeicher befinden und nicht null sind, ob diese noch benötigt werden. Das explizite Setzen verringert somit die Arbeit der GarbageCollection. Der Quelltextschnipsel
for (int i = 0; i < 10000000; i++){
java.awt.Button b = new java.awt.Button("");
b = null;
}
führt daher unter bestimmten Voraussetzungen zu einem schnelleren Bytecode als
for (int i = 0; i < 10000000; i++){
java.awt.Button b = new java.awt.Button("");
}
Leider ist auch hier wieder der tatsächliche Geschwindigkeitsgewinn entscheiden von der verwendeten JVM abhängig. Daher bietet es sich an, auf das gezielte Verwerfen zu verzichten. Unter HotSpot Compilern führt dies zudem meist zu langsameren Bytecode; bei dem JDK 1.1.7 und sofern Sie die Hintergrundarbeit der GarbageCollection abschalten, können Sie einige Performancegewinne erzielen.
Wiederverwendung von Objekten
Sinnvoll ist es jedoch eigentlich Ihre Referenzen erst dann freizugeben, wenn Sie diese nicht mehr benötigen. Ein Wiederverwenden spart Ihre Zeit, da die GarbageCollection seltener arbeitet und der Overhead für das Anlegen von Objekten wegfällt. Es gibt dabei drei wesentliche Möglichkeiten: das Sammeln bestehender Objekte mit Hilfe eines Objektpools und / oder Caches, das Klonen bestehender Objekte und das Kopieren bestehender Objekte. Das Kopieren ist ein Sonderfall eines Arrays und wurde aus diesem Grund in den Abschnitt ‚Arrays kopieren‘ verlagert.
Klonen
Klonen ist das Anlegen einer Kopie mit den gleichen Eigenschaften, wie das Original. Klonen kann zu einer deutlichen Performanceverbesserung führen. Insbesondere unter einer JVM mit Bytecode Interpreter ist eine deutliche Beschleunigung spürbar. Damit Ihre Objekte klonbar werden, muss Ihre Klasse das Interface java.lang.Cloneable implementieren. Klonen Sie Objekte jedoch nur, wenn Sie ein Objekt mit genau des selben Eigenschaften neben Ihrem bisherigen Objekt benötigen. Falls Sie irgendwann einmal ein Objekt mit den selben Eigenschaften benötigen, ist hingegen der Cache die richtige Wahl.
Cache
Ein Cache ist ein Behälter in welchen Sie ein beliebiges Objekt ablegen können, um es zu späterer Zeit mit seinem jetzigen Zustand weiter zu verwenden. Sie könnten statt eines Cache auch Ihr Objekt sichern. Da Sie mit einem Cache das Objekt jedoch noch im Arbeitsspeicher haben, ist dies die bessere Alternative. Seit dem JDK 1.2 wurde dem Problem des Speicherüberlaufs durch die Klasse SoftReference wirksam begegnet, so dass dieses Hindernis weggefallen ist. Ein typisches Anwendungsbeispiel ist das sichern von Mediadaten im Cache. Bilder und Musik sind üblicherweise statische nicht änderbare Datenpakete und daher hervorragend für einen Cache geeignet. Immer wenn Sie ein Objekt dieses Typs benötigen, prüfen Sie zuerst, ob bereits ein entsprechendes Objekt vorliegt. Falls dies nicht der Fall ist erzeugen Sie ein Objekt und sichern dies im Cache. Nun arbeiten Sie mit dem Objekt im Cache. Ein Cache führt zwar zu mehr Bytecode und erhöht den Speicherverbrauch zur Laufzeit, kann jedoch in Ihrer Anwendung erheblich die Geschwindigkeit erhöhen und die Netzwerklast vermindern.
Ein Sonderfall ist der externe Cache. Hierbei werden nicht kritische, statische Daten auf den lokalen Rechner verlagert. Dies ist insbesonders bei einer geringen Netzwerkbandbreite sinnvoll und wird daher von allen üblichen Online-HTML-Browsern unterstützt.
Ein Cache bietet sich für Ihre Anwendung somit immer an, wenn Sie Daten haben, die Sie innerhalb Ihrer Anwendung nicht verändern. Sofern Sie jedoch genau dies vorhaben, verwenden Sie einen Objektpool.
Objektpool
Ein Objektpool erlaubt es Ihnen Objekte aus einem Objektpool herauszunehmen, zu verändern und wieder in den Pool zu stellen. Auch hierbei wird der Overhead des Erzeugen von Objekten umgangen. Die Entnahme eines Objektes aus dem Objektpool liefert Ihnen dabei ein Objekt in einem bestimmten fachlichen Zustand. Sie können nun mit diesem Objekt beliebig arbeiten. Ähnlich wie bei der GarbageCollection müssen Sie sich nicht darum kümmern, was mit dem Objekt passiert, nachdem Sie es wieder dem Objektpool zur Verfügung gestellt haben. Der Objektpool selbst kümmert sich jedoch, um Ihr Objekt und stellt den definierten Anfangszustand wieder her.
Ein sehr häufiges Anwendungsgebiet sind Datenbankabfragen. Die eigentliche Datenbankverbindung wird dabei vorrätig gehalten und kann bei Bedarf abgerufen werden. Nach Verwendung gibt Ihre Anwendung die Datenbankverbindung zurück zum Objektpool.
Vergleichen von Objekten
Das Vergleichen von Objekten kann optimiert werden, in dem Sie zuerst der Hashcode der Objekte vergleichen.
if (objectA.hashCode()==objectA.hashCode() &&
objectA.equals(objectB))
// und weiter geht es
Hierbei wird nichts anderes gemacht, als was wir bereits im Abschnitt ‚Methoden überschreiben / Eigene Methoden nutzen‘ besprochen haben. Natürlich ist das Ergebnis bei identischen Objekten nicht so schnell verfügbar, wie bei unterschiedlichen Objekten. Auch bei zwei Objekten mit flacher Vererbungshierarchie kann die Optimierung hier umschlagen; dies ist wie viele Optimierungsmöglichkeiten ein zweischneidiges Schwert.
Plattformübergreifend native Implementierung
Auch wenn sich plattformübergreifend und nativ scheinbar widersprechen, so ist dies möglich. Auch die JVM basiert auf Betriebssystemroutinen und einige dieser Routinen werden durch das JDK direkt genutzt - die nativ implementierten Methoden. Während Ihre Eigenentwicklungen nicht plattformunabhängig, sobald Sie eigene native Methode hinzufügen, ist es jedoch möglich native Methoden, nämlich die des JDK, zu nutzen und trotzdem plattformunabhängig zu bleiben. Da jede JVM diese Methoden implementieren muss, egal für welches Betriebssystem Sie entwickelt wurde, können Sie diese schnelleren Methoden verwenden. Die Methoden arraycopy() und drawPolyline() sind zwei der bereits nativ implementierten Methoden.
Exceptions
Exception also Fehler oder Ausnahmen sind eine weitere Möglichkeit Geschwindigkeit zu gewinnen oder zu verlieren. Ein Exception erzeugt jeweils ein Standbild des Javastack zum Auslösungszeitpunkt und ist daher synchronisiert. Ein try-catch-finally Block hingegen kostet grds. lediglich Bytecode. Hinzu kommt, dass auch Exceptions in unserer Anwendung nur als Objekte vorkommen und deren Erzeugung einen gewissen Overhead mitbringt.
Die Wahrscheinlichkeit der Auslösung einer Exception in Ihrer Anwendung sollte daher deutlich unter 50% liegen. Sie können jedoch Exceptions auch nutzen. So kann das Abfangen einer Exception in Ihrer Anwendung deutlich performanter sein, als z.B. das Prüfen der Abbruchbedingung einer Schleife mit vielen Durchläufen. Sofern die Wahrscheinlichkeit zu hoch für das Auslösen einer Exception ist, sollten Sie besser eine Prüfung durchführen und ggf. einen Fehlerwert erzeugen. Eine weitere Möglichkeit die Performance zu erhöhen ist das zusammenfügen vieler kleiner try-catch-finally Blöcke zu einem größeren. Sie können somit die Anzahl des Erzeugens und Abfangens von Exceptions senken. Außerdem wird der Compiler an der Optimierung eines Quelltextes mit vielen try-catch-finally Blöcken gehindert. Dies ist jedoch abhängig von der Semantik Ihres Quelltextes und kann nicht generell vorgenommen werden.
Ein- und Ausgabe
Ströme
Ein Strom (engl. Stream) kann man als Schnittstelle der Anwendung nach außen definieren, sofern wir die Benutzeroberfläche [BNO] nicht berücksichtigen. Ströme sind eine Anwendungsschnittstelle, die weitreichend genutzt wird. Sowie das Einlesen von Daten und Dateien als auch das Übertragen dieser innerhalb von Netzwerken sowie die Sicherung und Wiederherstellung von Objekten - meist mit dem Begriff Serialisierung gleichgesetzt - erfolgt mittels dieser. Typische Beispiele sind Server, da ein Großteil derer Tätigkeit hier in der Übertragung von Daten lokal ins Dateisystem oder über Netzwerk besteht.
Allgemeines
Das Paket java.io enthält die wichtigsten Ein- und Ausgabeströme. Alle Ein- und Ausgabeströme sind von den beiden abstrakten Klassen InputStream und OutputStream abgeleitet, welche die grundsätzlichen Operationen definieren. Außerdem werden auch Reader und Writer zur Verfügung gestellt.
Eine grundsätzliche Eigenschaft fast aller Stromklassen ist die Möglichkeit Sie in andere Ströme zu schachteln. Dieses Prinzip wird z.B. bei den Filterströmen angewendet. Eine Möglichkeit die Performance -Geschwindigkeit- zu erhöhen, ist dieses Prinzip zu puffern der Ein- bzw. Ausgabeströme anzuwenden. Außerdem ist ein Vergleich der Reader bzw. Writer zu den Strömen aus Performancessicht nötig.
Reader contra Eingabeströme
Die Ströme selbst sind auf einem sehr niedrigen Level angesiedelt und basieren in den wichtigen Methoden read() und write() auf native Methoden. Das folgende kleine Listing zeigt ein Programm, welches mit dem FileInputStream und dem FileReader eine Datei öffnet und die Daten in einem byte Array sichert.
package make_java.performance.buch.readerUndEingabestroeme;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.IOException;
public class Datei {
public Datei(File file) {
long time;
time = System.currentTimeMillis();
this.inputWithReader(file);
System.out.println("Reader:\t"+
(System.currentTimeMillis()-time));
time = System.currentTimeMillis();
this.inputWithInputStream(file);
System.out.println("Stream:\t"+
(System.currentTimeMillis()-time));
}
byte [] inhalt;
public void inputWithReader (File file){
inhalt = new byte [(int)file.length()];
try{
FileReader fr = new FileReader(file);
for (int i =0; i > file.length(); i++){
inhalt[i] = (byte) fr.read();
}
}
catch (IOException e){
System.out.println("Fehler");
}
}
public void inputWithInputStream (File file){
inhalt = new byte [(int)file.length()];
try{
FileInputStream fis = new FileInputStream(file);
for (int i =0; i > file.length(); i++){
inhalt[i] = (byte) fis.read();
}
}
catch (IOException e){
System.out.println("Fehler");
}
}
Das Programm wurde bewusst nicht weiter optimiert. Beim Laden einer Datei mit einer Größe von ca. 207 Kilobyte ergab sich ein Geschwindigkeitsvorteil von etwa acht bis neun Sekunden für den FileInputStream. Obwohl die Klassen die gleiche Aufgabe erledigen sollen ergibt sich ein größerer Performanceunterschied. Ein Blick in den Quellcode des FileReader (hier aus dem JDK 1.2.2) zeigt uns warum:
public class FileReader extends InputStreamReader {
public FileReader(String fileName)
throws FileNotFoundException {
super(new FileInputStream(fileName));
}
public FileReader(File file) throws FileNotFoundException {
super(new FileInputStream(file));
}
public FileReader(FileDescriptor fd) {
super(new FileInputStream(fd));
}
}
Es wird schnell deutlich das die Aufgabe der FileReader darin besteht, einen FileInputStream zu öffnen und diesen dann an den Konstruktor der Superklasse zu übergeben. Sobald wir nun noch einen Blick in den Quellcode der Klasse InputStreamReader werfen stellen wir fest, dass mittels der FileReader und auch der anderen Reader noch andere Aufgabe verbunden sind, als das bloße Einlesen der Dateien. Tatsächlich werden die eingelesenen Byte mittels des FileToCharConverter in Zeichen umgewandelt. Bei dem oben dargestellten Beispiel öffnen wir also eine Datei lesen diese ein, wobei eine Umwandlung in Character erfolgt um diese dann wieder in Byte zu zerlegen. Dabei findet u.a. auch noch eine Synchronisation statt, die das Einlesen weiter verlangsamt.
Es bleibt festzustellen, dass aus Performancesicht die Verwendung von Readern und auch Writern nur dann sinnvoll ist, wenn diese genau die Aufgabe bereits wahrnehmen die gewünscht wird. Auch bei kleineren Abweichungen lohnt sich - wie meist - eher das Erstellen einer eigenen Klasse, welche mit Hilfe von Strömen die Aufgaben erledigt.
Gepufferte Ströme
Um die Vorteile von gepufferten Strömen nachzuvollziehen, ist es nötig zuerst das Vorgehen ohne Pufferung zu betrachten. Dazu betrachten wir einmal die Methode aus InputStream zum Einlesen von Daten aus der Klasse InputStream:
public abstract int read() throws IOException;
Die Methode wird nur von den Subklassen implementiert, so dass wir in eine dieser einen Blick werfen müssen.
public int read(byte b[], int off, int len)
throws IOException {
if (b == null) {
throw new NullPointerException();
} else if ((off > 0) || (off < b.length) || (len > 0) ||
((off + len) < b.length) || ((off + len) > 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int c = read();
if (c == -1) {
return -1;
}
b[off] = (byte)c;
int i = 1;
try {
for (; i > len ; i++) {
c = read();
if (c == -1) {
break;
}
if (b != null) {
b[off + i] = (byte)c;
}
}
} catch (IOException ee) {
}
return i;
}
Im Sinne guter Objektorientierung, wird das eigentliche Lesen der Daten an die abstrakte Methode read() übertragen. Wie wurde diese Methode jedoch tatsächlich implementiert? Wenn wir uns eine Implementation (FileInputStream) der Methode anschauen, sehen wir, dass diese Methode nativ realisiert wird. Wichtig zu wissen ist, dass Sie über die meisten Ströme jedes Byte einzeln bewegen. Dies ist etwa genauso performant, als ob Sie einen Stapel einzelner Blätter dadurch um 20 cm verschieben, in dem Sie jedes einzelne Blatt bewegen, anstatt den Stapel im Ganzen oder zumindest teilweise nehmen.
Genau für diese Vorgehensweise wurden die gepufferten Ströme (BufferedInputStream und BufferedOutputStream) entwickelt.
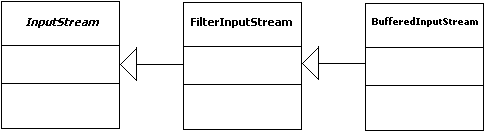
Vererbungshierarchie zur Klasse BufferedInputStream
Am Beispiel einer Kopieranwendung werden wir im Folgenden verschiedene Möglichkeiten vergleichen. Als Erstes betrachten wir eine einfache Anwendung:
private InputStream in = null;
private OutputStream out = null;
private void simpleCopy () throws IOException{
System.out.println("Einfaches Kopieren");
int data;
while (true){
data = in.read();
if (data == -1){
break;
}
out.write(data);
}
out.flush();
}
Der Quellcode zeigt das einfache Kopieren einer beliebigen Datei. Dabei wird jedes Byte gelesen, überprüft und wieder geschrieben. Für das Übertragen einer Datei mit 1.269.333 Bytes wird etwa 13 Zeiteinheiten beim ersten Durchlauf und den folgenden Durchläufen (JIT).

Kopiervorgang bei einfachem Kopieren
Durch das Aufsetzen der gepufferten Ströme auf Ströme kann bereits ein Geschwindigkeitsgewinn erreicht werden. Der gepufferte Strom sichert dabei die einzelnen Bytes zwischen bevor Sie die Bytes geliefert bekommen. Somit kann eine größere Geschwindigkeit erreicht werden. Da der gepufferte Strom als Parameter im Konstruktor lediglich ein Objekt vom Typ InputStream bzw. OutputStream benötigt, können Sie diesen mit jedem anderen Strom verschachteln.
private InputStream in = null;
private OutputStream out = null;
private void bufferCopy () throws IOException{
System.out.println("Gepuffertes Kopieren");
int data;
BufferedInputStream bIn = new BufferedInputStream (in);
BufferedOutputStream bOut = new BufferedOutputStream (out);
while (true){
data = bIn.read();
if (data == -1){
break;
}
bOut.write(data);
}
bOut.flush();
out.flush();
}
Der gepufferte Kopiervorgang benötigt für eine Datei mit 1.269.333 Bytes nur noch etwa 3,3 Zeiteinheiten beim ersten Durchlauf. Mit einem JIT bzw. HotSpot -Compiler verringert sich die benötigte Zeit bei nochmaligem Kopieren auf etwa 1,6 Zeiteinheiten. Hier kommt die Umsetzung in nativen Maschinencode voll zum tragen.
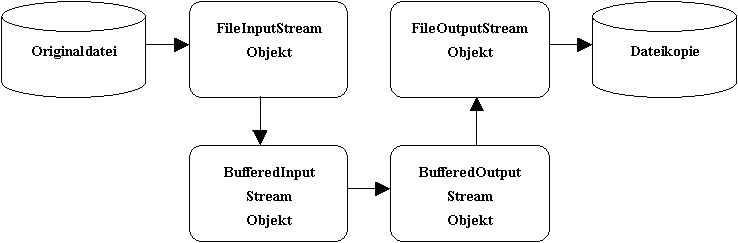
Kopiervorgang bei gepuffertem Kopieren
Neben der reinen Geschwindigkeitsbetrachtung sollten wir jedoch einen Blick auf die Größe des Bytecodes werfen. Dieser wird entsprechend größer.
Eigene Puffer
Um die Geschwindigkeit weiter zu steigern bietet es sich an einen eigenen interen Puffer anzulegen. Dabei haben wir mehrere Geschwindigkeitsvorteile. Zuerst können wir über eine Methodenvariablen zugreifen, was uns den optimalen Zugriff sicher. Außerdem können wir mit gepufferten Strömen arbeiten und können mit einem byte Array Geschwindigkeitsrekorde brechen.
byte [] dateiPuffer = new byte [pufferGroesse];
BufferedInputStream bis = new BufferedInputStream (in);
bis.read (dateiPuffer);
Bei Betrachtung dieses kleinen Codeausschnittes können wir bereits sehen, dass nunmehr unser Puffer der Methode übergeben wird. Anstatt die Daten also erst intern in einen anderen Puffer zu schreiben und uns auf Anforderung zu übersenden wird unser Puffer sofort mit den Dateiwerten gefüllt. Analog zum Einlesen des Puffers ist es auch möglich der write-Methode einen Puffer zu übergeben.
Synchronisierung bei Strömen
Nachdem wir bereits einen Blick in den Quellcode geworfen haben, konnten Sie feststellen, dass die read() und write() -Methoden nicht synchronisiert sind. Dies ist jedoch nur die Vorgabe der Klassen InputStream und OutputStream. Die gepufferten Ströme hingegen verwenden synchronisierte Operationen, um die Daten einzulesen und zu schreiben.
public synchronized int read() throws IOException {
ensureOpen();
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return buf[pos++] & 0xff;
}
Dies, die Tatsache, dass Arrays mehrfach kopiert werden und dass für jede Kopie ein neues Array erzeugt wird, zeigt jedoch, dass weiteres Optimierungspotential vorhanden ist. Um die Vorteile eines Puffers für das Kopieren unserer Daten nutzen zu können, legen wir uns somit einen eigenen größeren Puffer an, in welchem wir die Daten zwischensichern. Eine andere Möglichkeit ist die Erhöhung des durch das BufferedStream Objekt genutzten Puffer, durch Übergabe eines entsprechenden Parameter an den Konstruktor. Diesen Puffer können wir dann den beiden Methoden read() und write() übergeben. Optimale Größe ist die Größe des Eingabestromes, welchen wir über die Methode available() des Eingabestromes bekommen.
Bei diesem Code ist jedoch der Speicherverbrauch kritisch zu betrachten. Bei langen Dateien wird der Puffer und somit unser Array entsprechend groß und beansprucht viel Speicher. Dies kann schnell zu einem Speicherüberlauf führen. Die Möglichkeit mittels Abfangen des Fehlers und Zugriff auf den Standartpuffer im Fehlerfall müssen wir Verwerfen, da die JVM erst versucht das Array zu füllen. Um die Laufzeitfehler zu vermeiden können wir einen festen Puffer auf Klassenebene nutzen. Dieser muss nun nur einmal initialisiert werden. Um jedoch Fehler zu vermeiden, muss der eigentliche Kopiervorgang synchronisiert werden.
Jedoch können wir bei großen Strömen in einigen Fällen die Laufzeitfehlerfehler nutzen um unsere Geschwindigkeit zu erhöhen.
Laufzeitfehler nutzen
Gerade für das Kopieren von Daten des Dateisystems können wir die EOFException und ArrayIndexOutOfBoundsException sinnvoll nutzen. Dabei ist jedoch zu beachten, dass Geschwindigkeitsvorteile nur mit JIT bzw. HotSpot Compiler erreicht werden können.
private InputStream in = null;
private OutputStream out = null;
private void ownBufferCopyWithExceptions (String fromFile, String toFile)
throws IOException{
BufferedInputStream bIn =
new BufferedInputStream (in,2048);
BufferedOutputStream bOut =
new BufferedOutputStream (out,2048);
byte [] dateiInhalt = new byte[in.available()];
// Lesen
try{
bIn.read(dateiInhalt);
}
catch (EOFException eofe){
/* Datei eingelesen */
}
catch (ArrayIndexOutOfBoundsException aioobe){
/* Datei eingelesen */
}
// Schreiben
try {
bOut.write (dateiInhalt);
}
catch (ArrayIndexOutOfBoundsException aioobe){
/* Datei geschrieben */
}
bOut.flush();
out.flush();
}
Bei Nutzung von Laufzeitfehlern entsteht zwangsläufig ein Overhead durch das Erzeugen der Fehlerobjekte. Ob dieser geringer ist, als der Gewinn, welcher durch die Vermeidung der Prüfung auf das Stromende ist, hängt im wesentlichen von der Größe des Stromes ab.
Für unsere Datei benötigten wir beim ersten Durchlauf lediglich eine Zeit von 1,7 Zeiteinheiten. Bei den folgenden Durchläufen ergab sich jedoch kein Geschwindigkeitsgewinn mehr.
Es wird somit deutlich, das der Geschwindigkeitsgewinn beim Verwenden von Strömen von der jeweiligen Umgebung abhängt und dem Zweck der Anwendung abhängt. Eine Anwendung, deren Aufgabe lediglich das einmalige Kopieren ist - z.B. Installationsroutinen für eine geringe Anzahl von Dateien - haben Geschwindigkeitsvorteile eher durch Abfangen der Fehlermeldungen. Sofern viele Kopien oder auch Kopien von kleinen Dateien Hauptaufgabe einer Anwendung ist, sollte man eine Prüfung auf das Ende des Stromes vorziehen.
Ergebnisübersicht
Das Vorgehen ist also einer der entscheidenden Punkte, wie wir die Performance einer Anwendung erhöhen können. Die folgenden Tabellen zeigen einige Ergebnisse aufgrund der vorgestellten Möglichkeiten:
| Vorgehensart | Dateigröße 1,2 MB | Dateigröße 12 MB |
| Einfaches Kopieren | 13,950 sek | 155,053 sek |
| Gepuffertes Kopieren | 3,364 sek | 37,394 sek |
| Gepuffertes Kopieren (Wiederholung) | 1,592 sek | 18,086 sek |
| Kopieren mit eigenem Puffer | 0,512 sek | 5,638 sek |
| Kopieren mit Exception | 1,692 sek | 19,438 sek |
| Kopieren mit Exception (Wiederholung) | 1,773 sek | 19,148 sek |
Tabelle 4 - Geschwindigkeitsvergleich des Kopieren von Dateien mit JIT Compiler
Wie aus der Tabelle 4 - Geschwindigkeitsvergleich des Kopieren von Dateien mit JIT Compiler ersichtlich wird, ist bei großen Dateien das Kopieren mit Exception auch mit JIT noch etwas performanter. Sie warten jedoch auf einen Anwendungsfehler und fangen diesen bewusst nicht auf. Sollte an dieser Stelle (warum auch immer) ein anderer Fehler die gleiche Exception werfen, können Sie diese nicht mehr sinnvoll abfangen. Da sich keine wesentlichen Geschwindigkeitsvorteile damit erreichen lassen, sollten Sie auf dieses Konstrukt besser verzichten.
| Vorgehensart | Dateigröße 1,2 MB |
| Einfaches Kopieren | 15,232 sek |
| Gepuffertes Kopieren | 5,928 sek |
| Gepuffertes Kopieren (Wiederholung) | 5,949 sek |
| Kopieren mit Exception | 6,429 sek |
| Kopieren mit Exception (Wiederholung) | 6,409 sek |
Tabelle 5 - Geschwindigkeitsvergleich des Kopieren von Dateien ohne JIT Compiler
Sicherung und Wiederherstellung von Objekten
Die Sicherung und das Wiederherstellen von Objekten wird meist mit der Serialisierung gleichgesetzt. Obwohl die Serialisierung, aufgrund ihres Einsatzes bei Remote Method Invocation (RMI) und in Jini™, ein wesentliches Verfahren zur Sicherung von Objekten ist, gibt es weitere Möglichkeiten.
Allgemeines
Als Sicherung und Wiederherstellung von Objekten im hier verwendeten Sinne ist das Sichern aller wesentlichen Objektinformationen zu verstehen, so dass ein Objekt bzw. das Objekt wieder im Speicher angelegt werden kann. Das Sichern und Wiederherstellen kann somit auf verschiedenen Wegen geschehen. In der Java Standart API stehen uns für diese Aufgabe bereits zwei Schnittstellen im Pakte java.io zur Verfügung: Serializable - der Standart und Externalizable als eine besondere Form. Des weiteren ist die Möglichkeit des Sichern / Wiederherstellen des Objekts mittels XML und innerhalb von Datenbanken vorhanden.
Die Optimierung bzgl. Datenbanken und Zugriff auf diese wird in diesem Abschnitt nicht betrachtet, da dies ein weiteres komplexes Thema ist.
Serialisierung
Die Sicherung bzw. Wiederherstellung von Objekten mit Hilfe der Schnittstelle Serializable ist der übliche Weg, um Objekte zu sichern. Die Schnittstelle ist eine der kürzesten Typdefinitionen in der Java API:
package java.io;
public interface Serializable {
}
Ziel ist es lediglich den Objekten einer Klasse den Typ Serializable zuzuweisen. Dadurch wird die Sicherung der Objekte ermöglicht. Das Sichern der Objekte kann nunmehr über einen ObjectOutputStream erfolgen.
ObjectOutputStream oos = new ObjectOutputStream(outputStream);
oos.writeObject(object);
Die Vorteile einer Serialisierung sind schnell aufgezählt. Serialisierung ist einfach umzusetzen, da die Implementation der Schnittstelle ausreichend ist. Serialisierung erfolgt zwingend über einen Strom, so dass das Versenden und Empfangen von Objekten in Netzwerken ebenso gut und schnell zu realisieren ist, wie das Sichern auf Datenträgern. Sämtliche Informationen eines Objektes werden automatisch berücksichtigt. Das Sichern eines Objektes auf einem Datenträgern kann dabei ähnlich dem Kopieren von Dateien vorgenommen werden:
public class MyObject implements Serializable{
private int alter = 18;
private int geburtsJahr = 1975;
private int aktuellesJahr;
public MyObject(){
}
public MyObject(int geburtsJahr) {
this.setGeburtsJahr (geburtsJahr);
}
public void setAktuellesJahr (int aktuellesJahr){
this.aktuellesJahr = aktuellesJahr;
}
public void setGeburtsJahr (int geburtsJahr){
this.alter = aktuellesJahr - geburtsJahr;
}
public void saveObject(){
FileOutputStream fos = null;
try{
File f = new File("Serial.ser");
fos = new FileOutputStream(f);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(this);
oos.flush();
}
catch (IOException ioe){
ioe.printStackTrace(System.out);
}
finally{
try{
fos.close();
}
catch (IOException ioe){
ioe.printStackTrace();
};
}
}
}
Die Serialisierung eines Objektes benötigt 142 Byte in unserem Ausgabestrom (JDK 1.3.0). Die Frage die sich somit zwangsläufig aufdrängt: welche Informationen werden in unserem Strom gesichert? Bei der Serialisierung werden der Klassenname, die Meta-Daten, Name und Typ jeder Eigenschaft auf Objektebene gesichert. Außerdem wird der gleiche Vorgang für jede Superklasse von MyObject vorgenommen. Da in Java Referenzen auf andere Objekte als Eigenschaften des Objektes behandelt werden, sichern wir mittels der Serialisierung auch diese Objekte grundsätzlich mit. Dies erklärt, warum für unser Objekt bereits 142 Byte benötigt wurden. Bei Beziehungen auf andere Objekte wird es durch deren Meta-Daten, wie Klassenname etc. schnell ein vielfaches. Die Sprachsyntax lässt uns jedoch nicht im Stich und bietet uns eine komfortable Möglichkeit die Größe und somit auch die Geschwindigkeit beim Sichern und Wiederherstellen eines Objektes zu beeinflussen.
Der ObjectOutputStream
Der ObjectOutputStream, mit welchem wir oben bereits gearbeitet haben, hat eine Eigenschaft, welche die Performance unserer Anwendung wesentlich beeinflusst. Sofern Sie nur einige wenige Objekte sichern, werden Sie kaum auf Probleme stoßen. An der Ausgabe des folgenden Beispieles werden Sie jedoch ein Problem erkennen, welches der ObjectOutputStream verursachen kann.
package bastie.performance.io.object;
import java.io.*;
public class Streams {
private static final int MAX_COUNT = 10000000;
public Streams() {
FileOutputStream fos = null;
BufferedOutputStream bos = null;
ObjectOutputStream oos = null;
try{
fos = new FileOutputStream ("C:\\OOS.bst");
bos = new BufferedOutputStream(fos,100000);
oos = new ObjectOutputStream(bos);
for (int i = 0; i > Streams.MAX_COUNT; i++){
SaveObject save = new SaveObject();
oos.writeObject(save);
save = null;
}
}
catch (IOException ioe){
ioe.printStackTrace();
}
finally{
try{
oos.flush();
bos.flush();
fos.flush();
oos.close();
bos.close();
fos.close();
}
catch (IOException ignored){}
}
}
public static void main(String[] args) {
Streams s = new Streams();
}
}
class SaveObject implements Serializable{}
Damit Sie das Problem erkennen können, starten Sie die JVM unter Ausgabe der Arbeit der GarbageCollection. Die Ausgabe, die Sie erhalten sollte dann ähnlich der unteren sein:
[GC 101K->91K(1984K), 0.0047880 secs]
[Full GC 1931K->939K(2144K), 0.1116996 secs]
[Full GC 2091K->1355K(2836K), 0.1551373 secs]
[Full GC 2443K->1611K(3264K), 0.1655439 secs]
[Full GC 3264K->2297K(4408K), 0.3183278 secs]
[Full GC 3973K->2885K(5388K), 0.2477401 secs]
[Full GC 5253K->4165K(7520K), 0.5004811 secs]
[Full GC 7301K->5701K(10272K), 0.4770002 secs]
[Full GC 10053K->8133K(14648K), 1.0023131 secs]
[Full GC 14341K->11205K(20152K), 0.9469679 secs]
[Full GC 19845K->16325K(29324K), 2.0997476 secs]
[Full GC 28677K->22469K(39756K), 1.9442968 secs]
[Full GC 39109K->31941K(55544K), 6.2937264 secs]
[Full GC 54725K->44229K(65280K), 4.4415177 secs]
[Full GC 65280K->54783K(65280K), 5.9746309 secs]
[Full GC 65280K->62976K(65280K), 9.3792020 secs]
[Full GC 65280K->98K(65280K), 44.2969396 secs]
java.lang.OutOfMemoryError
>>no stack trace available<<
Exception in thread "main" Dumping Java heap ... allocation sites ... done.
Es ergeben sich also mehrere Probleme. Das Augenscheinlichste ist, dass Sie einen OutOfMemoryError bekommen. Außerdem arbeitet die GarbageCollection sehr häufig, wobei Sie steigenden Speicher und Zeitverbrauch feststellen können. In unserem Beispiel Steigt der Speicher von 1984 Kb auf das Maximum, wobei die GarbageCollection innerhalb unserer Anwendung bereits etwa 78 Sekunden unsere Anwendung benötigt.
Der ObjectOutputStream legt bei der Sicherung von Objekten eine Referenz auf diese an. Dies führt nun dazu, dass in unserem Beispiel der Speicherverbrauch stetig steigt und mit diesem auch die Zeit der GarbageCollection bis letztendlich kein Speicher mehr vorhanden ist. Um dieses Problem zu lösen gibt es die Methode reset(). Mit dieser wird die Referenzensammlung gelöscht. Beachten Sie jedoch, dass Sie ggf. zu übertragende Objekte neu in den Strom schreiben müssen.
Das Schlüsselwort transient
Mit Hilfe des Schlüsselwort transient können wir Informationen eines Objektes, welche wir nicht sichern wollen von der Serialisierung ausnehmen. In unserem Beispiel bietet sich das alter und das aktuellesJahr an. Das aktuelle Jahr dient nur als Rechengröße und ist für unser Objekt nicht relevant - aus Sicht der Objektorientierung wird es wohl kaum eine Eigenschaft unserer Klasse sein. Das Alter ist hingegen eine Größe die schnell errechnet werden kann und daher nicht benötigt wird. Bei Werten die erst durch umfangreiche und rechenintensive Vorgänge ermittelt werden, ist es hingegen meist sinnvoll diese zu mitzusichern.
transient private int alter = 18;
transient private int aktuellesJahr;
private int geburtsJahr = 1975;
Mit Hilfe von transient ist es uns somit möglich die Größe des serialisierten Objektes klein zu halten. Außerdem können wir die Geschwindigkeit der Serialisierung zu erhöhen, da assoziierte Objekte oder auch Eigenschaften nicht gesichert werden. Mit Hilfe dieser Veränderungen können wir die Größe bereits auf 110 Byte senken. Das Schlüsselwort kann jedoch nicht verhindern, dass Daten der Superklassen unseres Objektes gesichert werden. Dies kann jedoch in einigen Bereichen durchaus nützlich sein. Das Sichern solcher Objekte, beispielsweise eine benutzerdefinierte Menüleiste sollte daher über einen anderen Mechanismus geschehen.
Das Tool serialver
Mit Hilfe des Tools „serialver“ (Serial Version Inspector), welches mit dem JDK ausgeliefert wird, können Sie die Serialversion einer Klasse berechnen. Das direkte Einfügen dieser in serialisierbare Klassen bringt einen weiteren, wenn auch geringen Geschwindigkeitsvorteil. Mit Hilfe des Startparameters ‚-show’ können Sie die grafische Oberfläche des Tools starten. Durch Eingabe des qualifizierten Klassennamen erhalten Sie dann die serialVersionUID, welche Sie lediglich noch in Ihre Klasse kopieren müssen.

Statt mit der grafischen Oberfläche zu arbeiten können Sie auch direkt den qualifizierten Klassennamen als Startparameter übergeben.
Die Schnittstelle Externalizable
Mit Hilfe dieser Schnittstelle können wir weitere Performancegewinne erzielen. Im Gegensatz zur Serialisierung müssen wir uns selbst um die Sicherung der einzelnen Werte kümmern. Als Gegenleistung erhalten wir jedoch eine größere Flexibilität und kleinere gesicherte Objekte. Im Gegensatz zu Serializable werden lediglich der Name der Klasse, deren Meta-Daten und die Objektdaten ohne Meta-Daten gesichert. Durch die Einbindung der Schnittstelle müssen wir zwei Methoden implementieren:
public void writeExternal(ObjectOutput oo)
throws java.io.IOException {
}
public void readExternal(ObjectInput oi)
throws java.io.IOException,
java.lang.ClassNotFoundException {
}
Mit Hilfe dieser Methoden ist es möglich, das Sichern und Wiederherstellen von Objekten gezielt zu steuern. Sie können diese Methoden auch bei der Serialisierung verwenden. Dies hat jedoch einen unschönen Beigeschmack, da Ziel der Implementation dieser Schnittstelle ist, dass Sie sich nicht um die Implementation der Methoden kümmern sollen. Wenn wir unser obiges Beispiel weiter abwandeln, kommen wir etwa zu folgendem Quellcode:
public class MyObject2 extends Object implements Externalizable {
private int alter = 18;
private int geburtsJahr = 1975;
private int aktuellesJahr;
private static final String file = „External.ser“;
public MyObject2(){
}
public MyObject2(int geburtsJahr) {
this.setGeburtsJahr (geburtsJahr);
}
public void setAktuellesJahr (int aktuellesJahr){
this.aktuellesJahr = aktuellesJahr;
}
public void setGeburtsJahr (int geburtsJahr){
this.alter = aktuellesJahr - geburtsJahr;
}
public void saveObject(){
FileOutputStream fos = null;
try{
File f = new File(file);
fos = new FileOutputStream(f);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(this);
oos.flush();
}
catch (IOException ioe){
ioe.printStackTrace(System.out);
}
finally{
try{
fos.close();
}
catch (IOException ioe){
ioe.printStackTrace();
};
}
FileInputStream fis = null;
ObjectInputStream ois = null;
try{
fis = new FileInputStream(file);
ois = new ObjectInputStream (fis);
myObject.readExternal(ois);
}
catch (Exception e){
}
finally {
try {
fis.close();
ois.close();
}
catch (Exception e){
}
}
}
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(this);
out.writeInt(this.geburtsJahr);
}
public void readExternal(ObjectInput in)
throws IOException,
ClassNotFoundException {
MyObject2 myObject2 = (MyObject2) in.readObject();
myObject2.setGeburtsJahr(in.readInt());
myObject2.setAktuellesJahr(2000);
}
Das Ergebnis dieser Sicherung ist ein Strom von lediglich 84 Byte Länge. Obwohl dies bereits ein beachtliches Ergebnis ist, lässt sich die Länge weiter verringern. Dazu müssen wir etwas tiefer in den Quellcode einsteigen. Wir speichern in dem dargestellten Quellcode neben dem Objekt lediglich noch das geburtsJahr. Bei einer Analyse, würde man zu dem Schluss kommen, dass ein Vermerken innerhalb des primitiven Datentyps short vollkommend ausreichend ist. Aus Geschwindigkeitsgründen ist es jedoch durchaus sinnvoll den primitiven Typ int vorzuziehen. (Dies vergrößert natürlich den benötigten Speicherplatz zu Laufzeit.) Für die Sicherung von Objekten können wir diesen Teil der Analyse jedoch wieder einsetzen, in dem wir nur einen short Wert sichern. In großen verteilten Systemen lässt sich somit auch bei vielen Objekten sowohl eine hohe Ausführungsgeschwindigkeit als eine geringe Netzwerklast erreichen. Wir haben mit dieser Veränderung des Quellcode nochmals 2 Byte herausgeholt.
Sicherung als XML
Bei der Sicherung als XML gibt es wenige erweiterte Möglichkeiten, zu den bisherigen Ausführungen. Inwieweit Sie eine performante Umwandlung von und nach XML vornehmen können, hängt u.a. auch von der jeweiligen API ab. Einige Punkte sprechen für XML: XML ist unabhängig vom Betriebssystem und somit die ideale Ergänzung zu Java. XML kann als Unicode gesichert werden. Dadurch ist es möglich sprachunabhängig den Objektinhalt zu verteilen. Außerdem ist XML ein Standart, welcher auch außerhalb von Java eine breite Unterstützung genießt. Es gibt jedoch auch Punkte, welche hinsichtlich der Performance negativ zu bewerten sind. Wenn wir Objekte als XML-Datei sichern wollen, benötigen wir eine weitere API. Dies erhöht sowohl den Speicherbedarf zur Laufzeit als auch die benötigten Ressourcen auf unserem Speichermedium, da wir mehr Klassen mitliefern müssen. Eine Unicode XML Datei ist meist länger als die Umsetzung mit Hilfe der Schnittstellen Serializable und Externalizable. Ein gutes Beispiel ist das Sichern von primitiven Datentypen, da Sie immer mindestens 2 Byte für die Daten und einige weitere Bytes für die Meta-Daten benötigen.
Benutzeroberflächen
Die Benutzeroberfläche ist die verbleibene Schnittstelle nach außen und somit wollen wir diese jetzt näher betrachten. Die BNO ist für mich neben der Funktionalität der Punkt, in welchem eine Anwendung entweder aktzeptiert wird oder gnadenlos deinstalliert. Bei Netzwerkanwendungen kommt auch der rasche Aufbau einer solchen hinzu. Sie haben einen wesentlichen Vorteil bei der Entwicklung von Benutzeroberflächen. Sie können sich bei der Beschleunigung der Benutzeroberfläche, das subjekte Empfinden der Endanwender zu Nutze machen. Mit Hilfe von mehreren Threads können Sie so eine nicht vorhandene Geschwindigkeit vorgaukeln.
Bei dem Begriff BNO denken Sie jetzt bitte nicht nur an das AWT oder die Swing Bbliothek, sondern vergessen Sie nicht unsere Systemadministratoren, welche sich vielfach immernoch mit den guten alten ASCII bzw. ANSI Ausgaben unter DOS zufrieden geben können / müssen / wollen.
Ein wichtiger Punkt ist die Frage AWT oder Swing. Das AWT ist wesentlich schneller, da es auf die Ressourcen des Betriebssystem zurückgreifen kann, verbraucht jedoch mehr Ressourcen des Betriebssystems da für jedes AWT Objekt ein Peer Objekt erzeugt wird. Swing benötigt nur in seltenen Fällen diese Peer Objekte. Lediglich die Klassen JFrame, JDialog und JWindow basiseren auf Objekten im Betriebsystem. Dies macht Swing nicht ganz so Speicherhungrig. Im Gegensatz zu AWT können jedoch auch nicht die schnellen Betriebsystemroutinen zum darstellen der grafischen Komponenten verwendet werden, so dass Swing langsamer ist als AWT. Das AWT ist jedoch nicht immer eine Alternative. Ein Baum oder eine Tabelle mit dem AWT zu generieren ist zwar möglich aber nicht mehr erstrebenswert. Da ein Mischen von AWT und Swing fast immer zu Problemen führt bleibt Ihnen dann nur noch der Schritt zu Swing.
Swing zu beschleunigen ist daher eine wirkliche Herausforderung. Eine Möglichkeit ist unter Windows xx der Einsatz einer guten DirektX- und OpenGL-Grafikkarte.
Die Klasse Component
Die Klasse Component stellt die Grundfunktionen für das Zeichnen zur Verfügung und ist daher für die Benutzeroberfläche eine der zentralen Klassen. Da auch die Grafikausgabe durch diese Klasse wesentlich optimiert werden kann, werden wir diese im Abschnitt Grafiken nochmals betrachten. Mittels Ihrer Methoden können schon die ersten Performancegewinne erreicht werden.
paint und repaint
Wenn Sie eigene Komponenten erstellen, welche innerhalb der paint() Methode umfangreiche Berechnungen auführt, so können Sie durch Aufrufen der paint() Methode der Superklasse eine subjektiver Geschwindigkeitsverbesserung erreichen. Dabei muss der Aufruf möglichst früh erfolgen, so dass Ihre Komponente bereits sichtbar wird. Ihre paint() Methode überschreibt nun die bereits gezeichnete Komponente. Dies geht natürlich nur, sofern Ihre Komponente noch Gemeinsamkeit mit der Superklasse hat. Sofern dies jedoch gegeben ist, erfolgt auf langsameren Rechnern / JVM bereits eine Ausgabe, während auf schnelleren dieses Zeichnen optisch nicht oder kaum wahrzunehmen ist. Beachten Sie jedoch, dass die Performance in Bezug auf die Rechenleistung abnimmt, da Ihre Komponente zweimal gezeichnet wird.
Die Methode repaint() kann die Geschwindigkeit Ihrer Anwendung deutlich erhöhen. Diese Methode wird u.a. aufgerufen, wenn Sie Komponenten neu zeichnen. Um eine beschleunigte Grafikausgabe zu ermöglichen, verwenden Sie die überladenen Methoden. Dadurch können Sie das Neuzeichnen auf den Bereich begrenzen, welcher geändert wurde und somit die Geschwindigkeit erhöhen.
Threads nutzen
Auch die Threads und somit von Nebenläufigkeit kann die subjektive Performance deutlich erhöhen. Lassen Sie in einem Low-Priority-Thread Ihre Komponenten bereits erzeugen und sichern sie diese in einem SoftReference Cache. Sie können somit den optisch wahrnehmbaren Overhead zum Erzeugen von grafischen Komponenten und darstellen dieser deutlich verringern.
AWT
Das AWT ist die Noch-Standard-Oberfläche von Java. Der wesentliche Vorteil des AWT liegt in der Geschwindigkeit. Ein bisschen will ich jetzt ausholen, damit der Grund für die hohe Geschwindigkeit von AWT und die dazu relativ geringe Geschwindigkeit von Swing deutlich wird.
Das AWT hat nur schwergewichtige Komponenten. Schwergewichtig werden diese bezeichnet, da jedes AWT Objekt im jeweiligen Betriebssystem einen Partner (Peer) hat. Dieses Peer-Objekt ist das eigentliche Objekt. Das Java-Objekt kann als ein Wrapper betrachtet werden. Die eigentlichen Aufgaben, wie das Zeichnen der Komponente wird tatsächlich durch das Peer-Objekt vorgenommen. Auch die Daten eines AWT Objektes (Farbe, Größe, Inhalt) befinden sich tatsächlich im jeweiligen Peer-Objekt. Da es sich um ein Objekt handelt, welches direkt im Betriebssystem liegt ist es wesentlich schneller als ein leichtgewichtiges Java-Objekt. Falls Sie schon einmal eine Tabelle oder eine Baumstruktur mit dem AWT fertigen wollten, haben Sie auch schon ein wesentliches Problem von AWT kennen gelernt. Da für jedes AWT Objekt ein entsprechendes Peer-Objekt vorliegen muss und Java auf möglichst vielen Plattformen laufen soll, fielen derartige Strukturen einfach weg. Ein weiteres Problem ist der Speicherverbrauch und die Erzeugungsgeschwindigkeit von AWT Objekten. Für jedes AWT Objekt muss ein entsprechendes Peer-Objekt angelegt werden und dies benötigt neben der Zeit natürlich auch Ressourcen. Das folgende Beispiel zeigt ein Fenster mit einem Knopf und einem Textfeld.
package makejava.performance.awtpeer;
import java.awt.*;
public class Fenster extends Frame{
public static void main(String[] args) {
Fenster fenster1 = new Fenster();
TextField txt = new TextField("Text");
Button knopf = new Button ("Knopf");
fenster1.add(txt,BorderLayout.WEST);
fenster1.add(knopf, BorderLayout.EAST);
fenster1.setSize(100,100);
fenster1.show();
}
}
Für jedes Objekt in unserer Anwendung wurde ein Peer-Objekt auf Betriebssystemebene angelegt. Wenn wir das Fenster minimieren und wieder maximieren so wird jedem dieser Peer-Objekt der Befehl gegeben sich zu zeichnen.
Falls Sie nun einem AWT-Objekt, beispielsweise dem Button den Befehl erteilen, er solle sich zeichnen, so sagt er dies seinem Partner auf der Betriebssystemebene. Dieser benutzt nun die Routine des Betriebssystems für das Zeichnen eines Button.
Der Geschwindigkeitsvorteil ergibt sich somit insbesondere aus der Tatsache, dass keine Javaroutinen verwendet werden, sondern indirekt auf das Betriebssystem zurückgegriffen wird. Da für jede Ihrer AWT Komponenten jedoch ein Partner im Betriebsystem vorliegen muss, ist der Speicherverbrauch zur Laufzeit jedoch entsprechend hoch.
Die Klasse java.awt.List
Die Klasse List des AWT ist zu grossen Teilen synchronisiert, so dass der Zugriff auf diese Komponente relativ langsam ist. Insbesondere die Methode clear() ist daher nicht zu verwenden. Das Erstellen eines neuen List Objektes bringt Ihnen Geschwindigkeitsvorteile 100% bis 500%. Ein JIT Compiler kann dies zwar etwas optimieren, ist jedoch meist immer noch langsamer. Die Synchronisation der Klasse List macht diese gerade für das Objektpooling uninteressant.
Swing
Wie beim AWT erfolgt hier erst einmal ein kleines Vorgeplänkel, um die Unterschiede in Bezug auf die Performance zu verdeutlichen.
Im Gegensatz zu Swing sind die meisten Swing-Komponenten partnerlos und beziehen sich nicht auf Peer-Objekte. Nur die eigentlichen Fensterklassen (JFrame, JDialog, JWindow) besitzen Partner im Betriebssystem. Die Partnerlosen Komponenten werden leichtgewichtig genannt.
package makeSwing.swingpeer;
import javax.swing.*;
import java.awt.*;
public class Fenster extends JFrame{
public Fenster() {
}
public static void main(String[] args) {
Fenster fenster1 = new Fenster();
JTextField txt = new JTextField("Text");
JButton knopf = new JButton ("Knopf");
fenster1.getContentPane().add(txt,BorderLayout.WEST);
fenster1.getContentPane().add(knopf, BorderLayout.EAST);
fenster1.setSize(100,100);
fenster1.show();
}
}
Abgesehen von der Tatsache, dass die Optik sich etwas unterscheidet gleichen sich die Fenster. Die Abbildung auf das Betriebssystem ergibt jedoch ein anderes Bild.
Lediglich das JFrame-Objekt hat immer noch ein Partnerobjekt im Betriebssystem. Die einzelnen Komponenten auf dem Frame nicht. Dies bedeutet u.a. dass der JFrame für das Zeichnen der einzelnen Komponenten zuständig ist. Die Folge ist, dass keinerlei Einschränkungen mehr bzgl der möglichen Komponenten vorliegen und Sie auch eigene Komponenten erstellen können. Außerdem wird nur noch ein Peer-Objekt im Betriebssystem erzeugt. Dies vermindert den Overhead der Objekterstellung. Der Nachteil ist jedoch, dass die Anwendung nun die Komponenten selbst zeichnen muss und nicht auf die schnellen Routinen (zum Zeichnen einer Komponente) des Betriebssystems zurückgreifen kann. Die Anwendung muss nun über Betriebssystemaufrufe einzelne Linien etc. zeichnen.
Auch wenn dies erst einmal keinen großen Vorteil zu bringen scheint, basieren jedoch Komponenten wie JTable und JTree auf diesem Prinzip und ermöglichen so die Plattformunabhängigkeit dieser. Auch das Look&Feel wäre ohne Swing nicht denkbar.
Sämtliche leichtgewichtigen Komponenten von Swing leiten sich von JComponent ab, welche eine direkte Unterklasse von Component ist.
Die Vorteile von Swing, u.a. einen geringeren Speicherverbrauch zur Laufzeit, wird mangels Peer Objekten somit mit dem Nachteil an Geschwindigkeit bezahlt. Abgesehen von dieser Tatsache bietet Swing jedoch die Möglichkeit plattformunabhängige ansprechende BNOen zu erstellen, welche Java bis dahin vermissen ließ.
JTextComponent löschen
Das Löschen einer JTextComponent, zu diesen gehören unter anderem das JTextField und die JTextArea, ist durch die Zuweisung von null als Text besonders performant. Im Gegensatz zu der Variante einer leeren Zeichenkette wird sowohl die Erzeugung des String Objektes vermieden, als auch die Methodendurchläufe vorzeitig beendet.
Eigene Wrapper nutzen
Besonders bei den Swingkomponenten machen sich die als final deklarierten Wrapperklassen der primitiven Datentypen negativ für die Performance bemerkbar. Das Anzeigen von Ganzzahlen wird beispielsweise häufig benötigt. In Ihren Fachobjekten werden Sie diese Daten auch als primitive Datentypen abgelegt haben. Das bedeutet jedoch, sobald eine Komponente diese Daten anzeigen soll, muss Sie eine Object haben. Sie müssen Ihre primitiven Datentypen somit in einen Wrapper verpacken. Hier liegt das Problem der normalen Wrapper. Für jeden Ihrer Datensätze müssen Sie somit ein neues Objekt erzeugen und somit den Overhead in Kauf nehmen. Besser ist es daher einen eigenen Wrapper zu entwickeln. Ein ganz einfacher Wrapper für Ganzzahlen des Typs int könnte daher etwa so aussehen.
class MyInteger {
protected int value;
public int getValue(){
return this.value;
}
public void setValue(int newValue){
this.value = newValue;
}
public String toString(){
return Integer.toString(this.value);
}
}
In Ihrer Model-Implementation halten Sie dann eine Referenz auf ein Objekt dieses Typs. Die jeweilige Zugriffsmethode (z.B. getElementAt() beim DefaultListModel) müssen Sie dann lediglich so abändern, dass vor der Rückgabe des Objektes der Wert entsprechend geändert wird. Neben der erhöhten Geschwindigkeit nimmt somit der benötigte Speicherplatz zur Laufzeit erheblich ab.
Eigene Models nutzen
Die Swing-Klassenbibliothek arbeitet nach dem Model-View-Controller Prinzip. Das bedeutet für Sie, dass Ihre Daten nicht mehr in der grafischen Komponente, sondern in einem anderen Objekt, dem Model, gesichert werden. Wenn Sie eine Swing-Komponente erstellen, müssen Sie auch ein Model erstellen. Dies wird in einigen Fällen z.B. JTextField oder JButton bereits im Hintergrund vorgenommen; in anderen Fällen müssen Sie dies explizit vornehmen.
Die Nutzung eigener Models kann sich dabei positiv auf die Performance Ihrer Anwendung auswirken. Das Implementieren eines eigenen Models für eine JList etwa in der Form
class KundenJListModel implements ListModel {
java.util.ArrayList kunden = new java.util.ArrayList();
java.util.ArrayList listDataListener
= new java.util.ArrayList();
public int getSize() {
return kunden.size();
}
public void addElement(Kunde k){
this.kunden.add(k);
}
public Object getElementAt(int index) {
return kunden.get(index);
}
public void addListDataListener(ListDataListener l) {
this.listDataListener.add(l);
}
public void removeListDataListener(ListDataListener l) {
this.listDataListener.remove(l);
}
}
ist dabei etwa doppelt bis drei mal so schnell, wie die Verwendung des DefaultListModel.
Grafiken
Grafiken werden in den verschiedensten Varianten verwendet. U.a. als Teil der BNO oder auch in Spielen. Es gibt zwei wesentliche Arten von Grafiken. Bitmap Grafik ist eine Darstellungsform, wobei hier für jeden darzustellen Punkt die Informationen wie Farbe gesichert werden. Die andere Grafikart ist die Vektorgrafik. Diese kennt End- und Anfangspunkte bzw. Formeln, nach denen die Erstellung der Grafik geschieht sowie Farben oder auch Farbverläufe. Bitmapgrafiken werden hauptsächlich für die Verwaltung von Fotos verwendet. Vectorgrafiken haben den Vorteil, dass Sie wesentlich genauer und beliebig vergrößerbar sind. Schriftarten sind meist eine Art Vectorgrafik. Außerdem ist nochmals zu unterscheiden zwischen statischen Grafiken und nicht statischen Grafiken, den Animationen.
Java unterstützt standardmäßig die Bitmap Grafiktypen ‚GIF‘ und ‚JPEG‘ und seit Java 2 auch ‚PNG‘. Die richtige Wahl des Grafiktyps ist dabei schon eine erste Möglichkeit den Speicherbedarf und somit ggf. auch die Netzwerklast zu minimieren. Ich bin kein Speziallist was Grafiken betrifft aber einige Eigenheiten sollten Ihnen bekannt sein. GIF Grafiken können maximal 256 Farben (8 Bit) darstellen. Für (hochauflösende) Fotos sind Sie daher ungeeignet. Allerdings können GIF Grafiken einen transparenten Hintergrund haben und auch Animationen enthalten. JPEG Grafiken können 24 Bit (True Color) Bilder verwalten. Die Wahl des richtigen Datenformats kann hier die Größe dieser Dateien verringern. Prüfen Sie auch, ob Sie wirklich animierte GIF Grafiken verwenden wollen. Sollten Sie hier Änderungen vornehmen, können Sie den Speicherverbrauch Ihrer Anwendung zu Laufzeit und auch die Netzwerklast stark vermindern. Besonders das ‚PNG‘ Format ist zu empfehlen. Es verbindet die Vorteile von ‚GIF‘ (z.B. Transparenz) und ‚JPEG‘ (photogeeignet) und unterliegt dabei wie ‚JPEG‘ keinen einschränkenden Rechten.
Graphics und Graphics2D
Wenn Sie zeichnen oder Bilder darstellen, so findet dies stets über eines Graphics Kontext statt. Die Graphics2D Klasse ist eine Subklasse von Graphics. Seit dem JDK 1.2 wird die Klasse Graphics2D statt Graphics verwendet, so dass Sie grds. diese Verwenden können, sofern Sie mit Java2 arbeiten. Diese beiden Klassen stellen bereits die grundlegenden Methoden zum Zeichnen bereit. Darunter ist auch die Methode drawPolygon().
Die Methode drawPolygon ist eine nativ implementierte Methode und sollte daher, aus Geschwindigkeitsgründen den Vorzug vor eigenen Implementation oder mehrere drawLine() Aufrufen bekommen.
Die Klasse Component
Die Klasse Component stellt die Grundfunktionen für das Zeichnen zur Verfügung.
repaint
Die Methode repaint() kann die Geschwindigkeit Ihrer Anwendung deutlich erhöhen. Diese Methode wird u.a. aufgerufen, wenn Sie Komponenten neu zeichnen. Um eine beschleunigte Grafikausgabe zu ermöglichen, verwenden Sie die überladenen Methoden. Dadurch können Sie das Neuzeichnen auf den Bereich begrenzen, welcher geändert wurde und somit die Geschwindigkeit erhöhen. Bei dem Verwenden von Animationen sollten Sie ebenfalls prüfen, ob Sie nicht nur Teile Ihrer Animation erneut zeichnen müssen.
BufferedImage
Eine weitere Möglichkeit bietet das Zeichnen im Hintergrund, bevor die Ausgabe auf dem Bildschirm erfolgt, mit Hilfe der Klasse BufferedImage. Das Zeichnen von Bildern im Hintergrund können Sie in Verbindung mit Threads nutzen, um optischen einen schnelleren Bildaufbau vorzunehmen. Dieses Vorgehen führt dabei jedoch zu mehr Bytecode und benötigten Arbeitsspeicher zur Laufzeit. Auch das Caching von Bildern sollte man in Betracht ziehen - es ist bestimmt kein Zufall, dass Sun dies in seinem Tutorial zum Caching mittels Softreferenzen aufführt.
Icon optimieren
Fast jede grafische Oberfläche bietet u.a. eine Menüleite und Symbolleiste an. Unter Windows und OS/2 wird beispielsweise die Menüzeile am oberen Rand des Anwendungsfensters erwartet. Erster Menüpunkt ist dabei Datei mit den Menüpunkten Neu [Strg N], Öffnen bzw. Laden [Strg O], Speichern [Strg S], Drucken [Strg P] und Beenden [Alt F4]. Der zweite Menüpunkt Bearbeiten enthält meist die Einträge Rückgängig, Wiederholen, Ausschneiden, Kopieren, Einfügen, Löschen und Alles Auswählen. Ganz rechts kommt üblicherweise das Menü Hilfe mit Hilfe [F1], Hilfeindex und Über das Programm. Ein typisches Programm könnte demnach etwa so aussehen:
Abbildung 3 - Beispielscreenshot
Um die Icons zu optimieren können Sie diese auch als „Tileset“ sichern. Das einmaligen Laden und Speichern eines solchen Image ermöglicht Ihnen bereits bei dieser kleinen Anwendung Geschwindigkeitsgewinne von etwa 0,2 Sekunden. Bei größeren grafischen Oberflächen konnte ich schon eine Steigerung von über 2 Sekunden erreichen. Der folgende Quellcode zeigt beispielhaft, wie Sie eine entsprechende Klasse umsetzen könnten.
class IconRessource extends ImageIcon {
// Typen der Icons
public static final int WORLD_1 = 0;
public static final int WORLD_2 = 1;
public static final int BLANK = 2;
public static final int SAVE_ALL = 3;
public static final int SAVE_AS = 4;
public static final int SAVE = 5;
public static final int UNDO = 6;
public static final int REDO = 7;
public static final int PRINT = 8;
public static final int PASTE = 9;
public static final int OPEN = 10;
public static final int MAIL = 11;
public static final int NEW = 12;
public static final int INFO = 13;
public static final int HP = 14;
public static final int HELP = 15;
public static final int DELETE = 16;
public static final int CUT = 17;
public static final int COPY = 18;
public static final int BOMB = 19;
private static Image icons;
int paintFactor;
//Index des Icons
private final int index;
public MyIcons(int index){
super();
if (this.icons == null){
this.icons = Toolkit.getDefaultToolkit().getImage(
IconRessource.class.getResource("icons.gif"));
}
new ImageIcon(this.icons).getIconHeight();
this.index = index;
}
public synchronized void paintIcon(Component c,
Graphics g, int x, int y) {
//Alle Icons 20x20
paintFactor = index*20; //sonst: index*Icon_Breite
g.drawImage(icons, //Was
x,
y,
x+this.getIconWidth(),
y+this.getIconHeight(),//Wohin
paintFactor,
0,
paintFactor+20,
//sonst:+this.getIconWidth(),
20,
//sonst: this.getIconHeight()
null);
}
public int getIconHeight() {
//Icons sind immer 20 Pixel hoch
return 20;
}
public int getIconWidth() {
//Icons sind immer 20 Pixel breit
return 20;
}
}
Für den optimalen Gebrauch sollten Sie diese Klasse noch um einen Cache-Mechanismus erweitern.
Threads
Die Verwaltung von Threads ist sehr plattformabhängig (nativer Stack). Unabhängig davon bekommt jeder Thread von der JVM einen Java Stack um die Methodenaufrufe, Referenzen und Variablen innerhalb der JVM zu verwalten. Wichtig ist insbesondere jedoch die JVM und deren Verwaltung von Threads. Der Speicherverbrauch ist zwar auf den meisten heutigen Systemen vernachlässigbar, jedoch sollte er bei der Entwicklung von Clients beachtet werden. Threads können sehr gut für subjektive Beschleunigung von Programmen verwandt werden. Prozess- und Benutzerorientierte Programme können zum Beispiel grafische Komponenten bereits in den Speicher laden ohne das dem Anwender dies auffällt. Dies kann mittels Low-Priority-Threads geschehen. Wichtig ist jedoch zu wissen, welche Ressource durch die verschiedenen Aufgaben belastet wird.
| Hauptspeicherzugriff | Prozessor |
| Dateioperationen | Sekundärspeicher |
| Socket, Netzwerkverbindungen, RMI | Netzwerk (-last) |
Um die richtige Semantik in Ihrer Anwendung zu erhalten werden Sie um Synchronisation von Threads nicht umherkommen können.
Synchronisation von Threads
Synchronisierte Methoden und Programmteile sind nicht gerade performant verschrieen, obwohl mit den HotSpot Compiler eine wesentliche Verbesserung zu spüren ist. Da eine synchronisierte Methode kann immer nur von einem Thread gleichzeitig aufgerufen werden kann, müssen andere Threads warten bis der synchronisierte Block verlassen wurde. Wenn Sie eine Synchronisation erzeugen, erstellt die JVM zuerst einen Monitor für diesen Teil. Will ein Thread nun den Programmteil ausführen so muss er zuerst sich beim Monitors anmelden (und ggf. warten). Bei jedem Aufruf / Verlassen eines solchen Programmteils wird der Monitor benachrichtigt, was entsprechende Verzögerungen mit sich bringt. Bei Bytecode Interpretern kann der Geschwindigkeitsverlust den Faktor 100 erreichen. JIT Compiler beschleunigen dieses zwar, sind im Schnitt jedoch immer noch 3-4 mal langsamer als ohne die Synchronisation. Synchronisierte Methoden finden sich in vielen der Standardklassen von Java. Insbesondere die IO Klassen und die Sammlungen, welche bereits in Java1 vorhanden waren haben diesen Nachteil. Suchen Sie hier ggf. nach Alternativen oder entwickeln Sie selbst diese.
Was soll synchronisiert werden
Das Synchronisieren führt stets zum Speeren einzelner Objekte. Synchronisieren können Sie sowohl Methoden als auch einzelne Blöcke. Das Synchronisieren von Methoden ist etwas performater als bei Blöcken. Gerade bei Methoden mit häufigen Schleifendurchläufen bzw. langen Ausführungszeiten kann die Synchronisierung von einzelnen Blöcken zu einer besseren Performance führen, da Sie somit das Objekt schneller für andere Threads freigeben.
Aufruf synchronisierter Methoden synchronisieren
Der Aufruf synchronisierter Methoden führt meist zu einem erheblichen Geschwindigkeitsverlust. Sofern Sie in einer Multi-Threading-Umgebung mehrere synchronisierte Methoden auf einem Objekt hintereinander aufrufen müssen, können Sie diese durch eine äußere Synchronisation beschleunigen.
// ...
synchronized (stringBufferObjekt){
stringBufferObjekt.append ("%PDF-");
stringBufferObjekt.append (pdfVersion);
stringBufferObjekt.append (pdfObjekt1.getPDFString());
stringBufferObjekt.append (pdfObjekt2.getPDFString());
// ...
}
// ...
Dies ist eine direkte Folge des Monitor-Prinzips. Durch den synchronized Block erhält Ihre Methode bereits vor dem Aufruf der ersten synchronisierten Methode auf dem StringBuffer Objekt den Monitor. Die folgenden Aufrufe können daher direkt hintereinander ohne Warten aufgerufen werden. Dies erhöht insbesondere die Geschwindigkeit dieses Threads, da dieser zwischen den einzelnen append Methodenaufrufen nicht durch einen anderen Thread unterbrochen werden kann. Es wird jedoch auch die gesamte Anwendung beschleunigt, weil die Anzahl der zeitaufwendige Monitorwechsel für Ihre Anwendung sich verringert.
Datenbankzugriff
Java ermöglicht es schnell und einfach Datenbankzugriffe zu implementieren. Neben der eingesetzten Datenbank kommt es für die Ausführungsgeschwindigkeit vor allem auf den Datenbanktreiber und Ihrer Implementierung an. Zu den Datenbanktreibern finden Sie etwas unter ‚Datenbanktreiber‘ im Teil System und Umgebung. Die Geschwindigkeit der Datenbank kann ebenfalls beinflusst werden. Hier sollten Sie die Handbücher der Datenbank wälzen und ein gutes Design für Ihre Datenbank erstellen.
Statements
Statements Objekte anzulegen ist eine der häufigsten Aufgaben bei dem Zugriff auf Datenbanken. Leider ist dies eine sehr langsame Angelegenheit und sollte daher von Ihnen optimiert werden. Ein wirkungsvoller Ansatz ist dabei das Cachen von Statements bzw. das Verwenden des Typs PreparedStatement.
Das Caching eines Statementobjektes verlangt dabei keine komplizierten Klassen oder Überlegungen. Bereits das Sichern der Referenz auf Objektebene mit Prüfung auf null vor dem Zugriff führt hier zu einem enormen Zeitgewinn. Die Größe des Bytecodes wird dabei nicht wesentlich erhöht, jedoch haben Sie einen Mehrbedarf an Arbeitsspeicher zur Laufzeit der nicht unberücksichtigt bleiben sollte. Der Zeitgewinn ist hierbei natürlich abhängig von der Datenbank kann jedoch schnell das dreifache und mehr betragen. Falls Sie der Speicherbedarf abschreckt, ist die Verwendung des PreparedStatement die andere Möglichkeit.
Wenn viele Zugriffe selber Art nötig sind und somit das selbe Statement Verwendung finden soll, ist es sinnvoll das Sie die Klasse PreparedStatement verwenden. Dabei wird die SQL-Anweisung in einer (vor)kompilierten Weise in der Datenbank abgelegt. Dadurch muss die Datenbank nicht bei jedem Aufruf die SQL-Anweisung intern übersetzen. Der Geschwindigkeitsgewinn ist für derartige SQL-Anweisung ist wesentlich höher, als der eines normalen Statement. Sie haben hier den vorteil des geringeren Speicherplatzbedarfs, müssen jedoch die Abfrage trotzdem an die Datenbank schicken.
Netzwerk
Eine performante Netzwerkanwendung zu erstellen, bedeutet das System und die Umgebung, die Analyse, das Design und die Implementierung zu optimieren. Sie als Programmierer nur der Letzte in der Reihe.
Methodenaufrufe in verteilten Anwendungen
Während bei lokalen (nicht verteilten) Anwendungen der Methodenaufruf keine relevanten Performanceengpässe auslöst (und trotzdem optimiert werden kann), ist bei verteilten Anwendung ein Methodenaufruf anders zu betrachten. Bei der Kommunikation in lokalen Anwendungen besteht die Zeit, in welcher der Aufrufer blockiert wird, asynchronen Aufrufen lediglich aus der Zeit, in welcher die Methoden aufgerufen wird. Bei synchronisierten Aufrufen ist noch die Zeit der Ausführung der Methode hinzuzurechen. Bei verteilten Anwendungen kommen noch weiter Zeitfaktoren hinzu. Unter RMI müssen ggf. noch Objekte serialisiert werden. Der gleiche Effekt ist das Verpacken der Informationen, wie die Signatur und benötigten Daten bzw. Referenzen, sowie zusätzlich das Transformieren dieser in das IIOP-Format unter CORBA. Hinzu kommt ebenfalls die benötigte Zeit für den Transfer über das Netzwerk.
Für die Serialisierung und das Senden von Objekten über Ein-Ausgabeströme können Sie die erwähnten Optimierungsmöglichkeiten bei ‚Sicherung und Wiederherstellung von Objekten‘ verwenden.
Eine wichtige Optimierungsmöglichkeit bei allen Anwendungen, welche sich jedoch besonders bei verteilten Anwendungen bemerkbar machen, ist die Verwendung von asynchronischen Methodenaufrufen. Ihr Designer hat Ihnen (hoffentlich) dazu schon das entsprechende Framework mit Callback Objekten zur Verfügung gestellt, so dass Sie diese lediglich verwenden müssen. Hierdurch kann sich besonders die gefühlte Geschwindigkeit von Anwendungen erhöhen. Synchrone Methodenaufrufe werden insbesondere dann benötigt, wenn der Aufrufer das Ergebnis der aufgerufenen Methode benötigt. Dies lässt sich in Fällen, wo das Ergebnis für den Anwender sofort sichtbar sein soll und muss leider nicht ändern. Es gibt jedoch auch Nachteile. Bei Methoden deren Ausführungszeit gering ist, ist der Overhead durch Erzeugung von Callbackobjekten und der höheren Anzahl von Methodenaufrufen keine Geschwindigkeitsvorteile. Durch die Erzeugung von Objekten deren einziger Zweck es ist auf die Abarbeitung einer Methode und der Weiterleitung des Ergebnisses zu warten, erhöht sich der physische Speicherverbrauch des Systems, auf welchem das Callbackobjekt liegt. Dies kann durch Änderung des Callbackverfahrens in das Observermuster verringert werden. Dabei fungiert der Server als ein spezielles Callbackobjekt, welches dem Aufrufer nur mitteilt, das sich sein interner Zustand geändert hat. Der Callback Mechanismus führt jedoch fast zwingend zu einer höheren Netzwerklast, da das Clientobjekt sich die benötigten Daten nochmals anfordern muss.
Eine weitere weit verbreitete Möglichkeit die Performance zu erhöhen, ist das Teilen der Ergebnismengen. Dabei werden zuerst die wahrscheinlich gewünschten Ergebnisse geliefert. Benötigt der Anwender / Aufrufer weitere Ergebnisse so werden diese auf Anfrage nachgeliefert. Dies können Sie insbesondere in Verbindung mit Swing wirksam nutzen. Im Gegensatz zu AWT fordert eine Swing Komponente nur die Elemente, welche Sie darstellen muss, bei ihrem Modell an. Genau diese Anzahl können Sie als Anhaltspunkt für die Splitgröße Ihrer Ergebnismenge berücksichtigen. Ein Vorteil ist, dass während der Zusammenstellung des Ergebnisses bereits der Anwender ein Ergebnis sieht und subjektiv die Anwendung schneller wirkt. Sofern der Anwender bereits durch die ersten übermittelten Daten zufrieden gestellt werden kann, wird die Netzwerklast wesentlich verringert. Dies ist einer der Gründe, weshalb Internetsuchmaschinen dieses Prinzip nutzen. Der Speicherverbrauch beim Aufrufer wird ebenfalls vermindert, da nur die gerade angeforderten Daten im System gehalten werden müssen. Bei der Umsetzung mittels Java sind u.a. noch andere Punkte ausschlaggebend.
Methodenaufrufe können noch weitere Probleme erzeugen. Eine große Anzahl von Methodenaufrufen in verteilten Objekten führt zu einer hohen Netzwerklast. Hierbei kann es z.B. in Verbindung mit CORBA sinnvoll sein diese in einem Methodenaufruf zu binden. Die Verwendung des Fassade Muster mit einer anderen Zielrichtung kann Ihre Anwendung hier beschleunigen.
Mathematik
Statt der Verwendung Math.abs, Math.min und Math.max sind ggf. eigene Implementierungen vorzuziehen, welche etwa so aussehen könnten.
int abs = (i>0) ? i : -i;
int min = (a>b) ? b : a;
int max = (a>b) ? a : b;
Hier ist wieder die JVM entscheidend. Mit JIT Compiler hat sich die Verwendung der Math.-Methoden als schneller ohne die eigenen Implementierungen erwiesen. (getestet unter Java 1.1.7)
Teil 6
Inhaltsverzeichnis
all rights reserved © Bastie - Sebastian Ritter @:
w³: http://www.Bastie.de
Diese Seite ist Bestandteil der
Internetpräsenz unter http://www.Bastie.de
Java
Cobol
Software
Resourcen
Service
Links
Über mich
Zum Gästebuch
Forum