Make Java - Performance
Teil 5
Design und Performance
Design ist ein Thema, welches sich immer (wieder) großer Beliebtheit erfreut. Betrachtet werden dabei jedoch meist die Vor- und Nachteile in Bezug auf Wartbarkeit, Entwicklungszeit und Fehleranfälligkeit. Unbestritten haben Entwurfsmuster Vorteile. Die entwickelte Anwendung baut auf einem bereits bekannten und erfolgreich eingesetzten Prinzip der Klassenmodellierung auf. Dadurch wird die Fehleranfälligkeit und Entwicklungszeit deutlich verringert, während die Wartbarkeit zunimmt. Nur selten fließen dabei jedoch Performancebetrachtungen ein. Diesem Thema werden wir im folgenden nachgehen.
Das Optimieren des Designs ist dabei Grundlage für eine optimal performante Anwendung. Ihre Designentscheidungen beeinflussen wesentlich die Performanceeigenschaften Ihrer Anwendung in bezug auf benötigte Bandbreite, Arbeitsspeicher und auch Geschwindigkeit. Eine performante Anwendung kann natürlich auch ohne das optimale Design entstehen und ein optimales performantes Design hat nichts mehr mit Objektorientierung zu tun, wie wir sehen werden. Trotzdem ist es sinnvoll zumindest einen Blick auf Performancemöglichkeiten im Design zu werfen.
Vor- und Nachteile
Der große Vorteil in einem performanten objektorientierten Design ist, dass Sie sich die Vorteile der Objektorientierung waren und gleichzeitig eine performante Anwendung entwickeln können. Objektorientierte Anwendungen gelten allgemein als wesentlich langsamer als Programme, welche mit herkömmlichen Programmiersprachen / bzw. -konzepten entwickelt wurden. Dies muss nicht sein. Leider müssen Sie dazu Ihr ansonsten gutes OOD nochmals betrachten und ggf. abändern. Zudem ist der Schritt von einem performanten objektorientierten Design zu einem performanten „Etwas“ nicht sehr groß. Hier heißt es Mäßigung üben. Auf einige der Stolperstellen gehen wir zum Schluss des Teils noch mal ein.
Datentypen
Im Design werden unter anderem die Datentypen festgelegt. Aus diesem Grund ist hier eine gewisse Grundkenntnis der JVM nötig, um performante Datentypen zuzuweisen.
Die JVM ist stackorientiert, wobei dieser Stack 32 Bit breit ist. Das bedeutet, dass 32 Bit breite Datentypen schneller verarbeitet werden können. Eine Fließkommazahl wird nicht so schnell verarbeitet wie Ganzzahlen. Weiterhin ist zu beachten, dass lokale Variablen wesentliche schneller verarbeitet werden können. Bei diesen ist zusätzlich zu beachten, ob es sich um Slotvariablen handelt. Die ersten 128 Bit, welche sich auf dem Slot befinden können mittels speziellem Code in der JVM besonders performant verarbeitet werden, so dass sich diese z.B. als Zählvariablen anbieten. Der Slot wird dabei nach einer bestimmten Reihenfolge gefüllt. Handelt es sich um eine Objektmethode so enthalten die ersten 32 Bit eine Referenz auf das Objekt. Die folgenden Bits werden zuerst mit den Parametern und dann mit lokalen Variablen aufgefüllt. Sammlungen sind dabei lediglich als Referenzen zu verstehen. Die Slotvariablen machen sich jedoch nur bei Java Interpretern deutlich bemerkbar.
Primitive und Referenzen
Da der Typ int und Referenzen jeweils 32 Bit breit sind, werden diese am schnellsten verarbeitet. Der Typ float kann als Fließkommazahlen nicht so performant verarbeitet werden. Die Typen long und double sind jeweils 64 Bit breit. Die verbleibenden primitiven Datentypen boolean, byte, short und char werden intern in den Typ int, für jede mit ihnen auszuführenden Operation, gecastet. Für die Operationen inkl. Laden und Sichern wird hier der selbe Bytecode verwendet, wie beim Typ int Nach Abschluss dieser werden sie zurück in den Ursprungstyp gecastet. Aus diesem Grund sind diese Typen, wenn es um Geschwindigkeit geht, zu vermeiden. Der benötigte Speicherbedarf entspricht jedoch dem Typen.
Als Designer obliegt es Ihnen somit zu prüfen, ob Sie einen Ganzzahltypen, auch wenn er als mögliche Wertbereiche beispielsweise nur 0..10 hat, als Javatyp int deklarieren. Dies kann zu erheblichen Geschwindigkeitsvorteilen führen. Natürlich sollen Sie die Fachanforderungen dabei nicht außer Acht lassen. Diese können in bezug auf andere Performancepunkte, wie Netzwerklast genutzt werden.
Besonderheiten in Arrays
Arrays haben eine etwas abweichende Speichernutzung. Datentypen nehmen auch hier grundsätzlich den Platz ihres Typs ein. Die Typen short und char werden dabei mit einer Breite von 16 Bit verwaltet. Verwenden Sie ein Array als Behälter für boolean oder byte Werte, so nehmen beide Typarten eine Bitbreite von 8 ein.
Sammlungen
Sammlungen oder auch Collections sind einige der Klassen / Objekte, welche mit am häufigsten Verwendung finden. Da Sammlungen auch nur bestimmte Datentypen sind, welche andere Datentypen in primitiver Form oder als Referenzen beinhalten, müssen Sie einige Einzelheiten wissen, um einen geeigneten Datentyp als Designer auszuwählen.
Synchronisiete Sammlungen
Bis zum JDK 1.2 hatten Sie keine große Auswahl. Seit dem hat sich jedoch eine Menge getan. Es wurde der Typ java.util.Collection in Form eines Interfaces eingeführt. Auch die bisherigen Typen, wie Vector wurden entsprechend angepasst. Bis zum JDK 1.2 bedeutet die Verwendung von Sammlungen immer auch Synchronisation. Wollen Sie diese verhindern, so mussten Sie zwangsweise eigene Klassen verwenden. Den Quelltext dieser können Sie dabei von den synchronisierten Klassen übernehmen. Ab dem JDK 1.2 hat sich eine Wendung vollzogen. Sammlungen sind grds. nicht synchronisiert. Dies erhöht die Zugriffsgeschwindigkeit enorm. Lediglich die aus dem alten JDK Versionen übernommenen Klassen wurden dahingehend nicht verändert. So ist die Klasse Vector immer noch synchronisiert. Es wurden für diese jedoch entsprechende nicht synchronisierte Sammlungen eingeführt.
Es ist aber für viele Aufgaben durchaus sinnvoll bzw. nötig mit synchronisierten Sammlungen zu arbeiten. Dies stellt jedoch keine großen Anforderungen an die Implementierung dar. Mit Hilfe der Fabrikmethoden der Klasse java.util.Collections können Sie synchronisierte Sammlungen erzeugen.
// Beispiel synchronisieren einer TreeMap
TreeMap treeMap;
treeMap = (TreeMap)Collections.
synchronizedSortedMap(new TreeMap());
Beim Aufruf einer Methode wird die Synchronisation durch den von Ihnen soeben erzeugten Wrapper bereit gestellt. Dieser leitet daraufhin den Aufruf an Ihre ursprüngliche Sammlung weiter. Die beiden Klassen Hashtable und Vector wurden zwar nachträglich an das Collection-Framework angepasst, sind jedoch weiterhin synchronisiert. Aber auch hier hat Sun Microsystems an Sie gedacht. In der Beschreibung zur Sammlung ArrayList ist daher folgendes zu lesen: „This class is roughly equivalent to Vector, except that it is unsynchronized.“ ArrayList ist somit der nicht synchronisierte Vector. In der Dokumentation zur Klasse HashMap finden wir schließlich folgenden Satz „The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.“
Gegenüberstellung von Sammlungen
| nicht synchronisiert | synchroisiert |
| HashSet | |
| TreeSet | |
| ArrayList | Vector |
| LinkedList | Stack |
| HashMap | Hashtable |
| WeakHashMap | |
| TreeMap | |
Sammlungen eignen sich grundsätzlich nur für Objekte. Sollten Sie eine große Anzahl von primitiven Datentypen sichern wollen ist ein Array die bessere Alternative.
Nicht jede Sammlung ist für jeden Zweck geeignet. Werden die Elemente einer Sammlung häufig durchlaufen, so ist die LinkedList mit einer besseren Performance ausgestattet als die ArrayList.
Versteckte Sammlungen
Das sich die Sammlungen nicht für primitive Datentypen eignen, liegt daran, dass eine Sammlung nur Objekte aufnehmen kann. Die Entwickler von Java wollten sich jedoch offenbar nicht dieser Einschränkung unterwerfen und haben sich daher eine Hashtable für int Werte geschrieben.
Die IntHashtable
Diese Hashtable ist versteckt im Paket java.text. Da Sie netterweise final deklariert ist, ist ein Aufruf leider nicht möglich. Hier hilft nur „Copy & Paste“. Die Verwendung dieser Klasse ist jedoch wesentlich performanter als das Verpacken von int Werten in Integer.
Erweiterungen
Es gibt Punkte, welche in der Analysephase keine oder nur geringe Beachtung verdienen, jedoch für eine performante Anwendung zu berücksichtigen sind.
Hierzu zählen insbesondere die Prüfung des Einbaus von Caches bzw. Objektpools.
Cache
Ein Cache ist einer sehr effiziente Möglichkeit die Geschwindigkeit einer Anwendung zu erhöhen. Ein Cache ist hier als halten einer Referenz auf ein Objekt einer Klasse zu verstehen. Immer wenn Sie ein Objekt dieser Klasse benötigen, prüfen Sie zuerst, ob bereits ein entsprechendes Objekt vorliegt. Falls dies nicht der Fall ist erzeugen Sie ein Objekt und sichern dies im Cache. Nun arbeiten Sie mit dem Objekt im Cache. Das Erzeugen von Objekten ist eine sehr zeitaufwendige Angelegenheit. Um ein Objekt zu erzeugen müssen die Konstruktoren der Klasse und aller Superklassen verarbeitet werden. Dies führt zu einem enormen Overhead, welcher durch einen Cache in der Anzahl verringert wird.
Ein Cache bietet sich für Netzwerkanwendungen an, da so die Netzwerkkommunikation minimiert werden kann. Objekte können lokal beim Client im Cache gehalten werden und müssen nicht bei erneutem Gebrauch wieder über das Netzwerk geladen werden. Bei Applets bietet sich diesen Vorgehen z.B. bei Multimediaobjekten wie Bilder und Musik an.
Objektpool
Ein Objektpool kann ebenfalls eine Anwendung wesentlich beschleunigen. In einem Objektpool befinden sich Objekte in einem definierten Ausgangszustand (anders Cache). Objekte, die sich in einem Objektpool befinden, werden aus diesem entliehen und nach der Verwendung wieder zurückgegeben. Der Objektpool ist dafür zuständig seine Objekte nach dem Gebrauch wieder in den vordefinierten Zustand zu bringen.
Für die Verbindung zu Datenbanken sind Objektpools gut zu verwenden. Eine Anwendungen / ein Objekt, welches eine Anbindung zur Datenbank benötigt entleiht sich ein Objekt, führt die nötigen Operationen aus und gibt es wieder an den Objektpool zurück.
Caches und Objektpools bieten eine gute Möglichkeit Ihre Anwendung zu beschleunigen.
Ein Cache sollten Sie verwenden, wenn der Zustand eines Objektes / einer Ressource für Ihre Anwendung nicht von Interesse ist.
Objektpools sollten Sie in Ihrer Anwendung verwenden, wenn Sie Objekte / Ressourcen mit einem definierten Zustand benötigen.
Netzwerkdesign
Auch für das Netzwerk müssen Sie als Designer bestimmte Überlegungen anstellen. Sobald Sie Daten über ein Netzwerk austauschen können bisher kleinere Performanceeinbussen sich deutlicher auswirken. Hier müssen Sie als Designer einige Punkte optimieren bzw. vorsehen, die während der Analyse vorbereitet wurden. Während bei lokalen (nicht verteilten) Anwendungen der Methodenaufruf keine relevanten Performanceengpässe auslöst (und trotzdem optimiert werden kann), ist bei verteilten Anwendung ein Methodenaufruf anders zu betrachten. Bei der Kommunikation in lokalen Anwendungen besteht die Zeit, in welcher der Aufrufer blockiert wird, asynchronen Aufrufen lediglich aus der Zeit, in welcher die Methoden aufgerufen wird. Bei synchronisierten Aufrufen ist noch die Zeit der Ausführung der Methode hinzuzurechen. Bei verteilten Anwendungen kommen noch weiter Zeitfaktoren hinzu. Unter RMI müssen ggf. noch Objekte serialisiert werden. Der gleiche Effekt ist das Verpacken der Informationen, wie die Signatur und benötigten Daten bzw. Referenzen, sowie zusätzlich das Transformieren dieser in das IIOP Format unter CORBA. Hinzu kommt ebenfalls die benötigte Zeit für den Transfer über das Netzwerk.
Bei einer verteilten Anwendung wirken sich bestimmte Modellierungen wesentlich Performancekritischer aus, als bei lokalen Anwendungen. Eine enge Kopplung von Objekten bedeutet hier nicht nur viel Kommunikation zwischen den Objekten sondern auch eine höhere Netzwerkauslastung. Dies können Sie durch verschiedene technologische Ansätze bzw. Verbesserungen und durch ein gutes Design optimieren.
Callback
Wenn Sie sich bei der Analyse die Arbeit gemacht haben, um die asynchronen von den synchronen Methodenaufrufen zu trennen, werden Sie als Designer nun die Möglichkeit haben die Infrastruktur aufzubauen.
Callbacks sind eine (in CORBA bereits weit verbreitete) Möglichkeit die Netzwerklast zu verringern. Dabei wird dem Server eine Referenz auf den Client übergeben. Während ansonsten der Client in regelmäßigen Abständen den Server nach Neuigkeiten fragt, informiert nunmehr der Server den Client über Änderungen die für Ihn relevant sind. Optimalerweise verbindet man das Ganze noch mit dem Observer-Pattern (Beobachter-Muster) um den Server unabhängig vom jeweiligen Client zu machen.
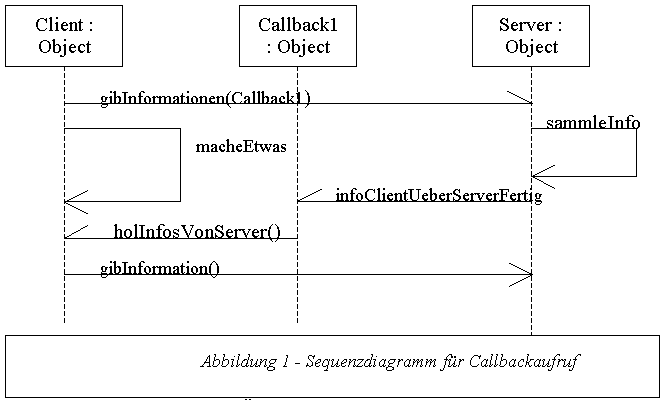
Das Callback-Objekt und Client-Objekt befinden sich dabei lokal. Bei der Anfrage an den Server-Objekt wird dem Server das Callback-Objekt übergeben und durch den Client mit seiner weiteren Aufgabe fortgefahren. Ihr Server-Objekt führt nun ohne das Client-Objekt zu blockieren die aufgerufene Methode aus. Nachdem diese ausgeführt wurde benachrichtigt er das Callback-Objekt. Dieses ruft nunmehr auf dem Aufrufer eine entsprechende Methode auf. Die Vorteile sind dabei klar erkennbar. Während es normalerweise zu einem Blockieren des Aufrufer bis zur Abarbeitung der aufgerufenen Methode kommt kann dieser weiter arbeiten.
Natürlich muss man auch hier die bessere Netzwerkperformance mit einem mehr an Bytecode bezahlen. Dies dürfte jedoch bei den meisten Anwendungen - und den heutigen Rechnern - eher in den Hintergrund treten. Bei kurzen Antwortzeiten können Sie jedoch die Performance Ihrer Anwendung verschlechtern. In diesen Fällen kann der Overhead der Netzwerkübertragung nicht durch das nebenläufige weiterarbeiten des Client ausgeglichen werden. Noch besser ist es eine entsprechende Adapterklasse zu erstellen. Diese wird über das Netzwerk angesprochen und kann nun ohne den Netzwerkoverhead das lokale Objekt Meier ansprechen.
Um den Overhead durch die Netzwerkübertragung zu verringern, sollten Sie ein weiteres Augenmerk auf die Methodenaufrufe legen.
Methodenaufruf
Eine wichtige Optimierungsmöglichkeit bei allen Anwendungen, welche sich jedoch besonders bei verteilten Anwendungen bemerkbar machen, ist die Verwendung von asynchronischen Methodenaufrufen (siehe Callback und Asynchrone Methodenaufrufe).
Eine weitere weit verbreitete Möglichkeit die Performance zu erhöhen, ist das Teilen der Ergebnismengen. Dabei werden zuerst die wahrscheinlich gewünschten Ergebnisse geliefert. Benötigt der Anwender / Aufrufer weitere Ergebnisse so werden diese auf Anfrage nachgeliefert. Ein Vorteil ist, dass während der Zusammenstellung des Ergebnisses bereits der Anwender ein Ergebnis sieht und subjektiv die Anwendung schneller wirkt. Sofern der Anwender bereits durch die ersten übermittelten Daten zufrieden gestellt werden kann, wird die Netzwerklast wesentlich verringert. Sofern Sie eine Informationssystem entwickeln werden Sie, ein derartiges Verfahren vermutlich verwenden. Dies ist einer der Gründe, weshalb Internetsuchmaschinen dieses Prinzip nutzen. Der Speicherverbrauch beim Aufrufer wird ebenfalls vermindert, da nur die gerade angeforderten Daten im System gehalten werden müssen. Bei der Umsetzung mittels Java sind u.a. noch andere Punkte ausschlaggebend. Stellen Sie sich eine Personenrecherche in einem umfangreichen System vor, die einige hundert Ergebnisse liefert, die Sie optisch darstellen wollen. Hier kann der Aufbau der entsprechenden grafischen Komponente Ihr System ausbremsen.
Methodenaufrufe können noch weitere Probleme erzeugen. Eine große Anzahl von Methodenaufrufen in verteilten Objekten führt zu einer hohen Netzwerklast. Hierbei kann es insbesondere in Verbindung mit CORBA sinnvoll sein diese in einem Methodenaufruf zu binden. Hierbei bieten erweitern Sie die Schnittstelle Ihrer Klasse bzw. Ihres Subsystem derart, dass Sie für mehrere Operationsaufrufe eine gemeinsame Operation anbieten.
Der Vorteil liegt in der Senkung des Overheads bei einem Methodenaufruf. Da die Daten für das Senden über das Netzwerk zuerst verpackt werden müssen, können Sie hier Performancegewinne erreichen. Hier bieten sich gerade bei RMI weitere Möglichkeiten, die im Teil Implementierung Sicherung und Wiederherstellung von Objekten genauer betrachtet werden.
Das Vorgehen entspricht dem Fassade-Muster, da die Kommunikation hier durch eine kleinere einheitliche Schnittstelle verringert wird. Dies lässt sich neben der Erweiterung der Schnittstelle auch durch eine Verkleinerung erreichen, indem ein Objekttyp zum Übertragen verwendet wird, welcher die benötigten Informationen beinhaltet. Des selbe Ansatz lässt sich auch durch das Verpacken in XML Dokumente umsetzen.
Entwurfsmuster
Auch die sogenannten Entwurfsmuster können bei der Erstellung von performanten Anwendungen helfen. Wir haben im vorigen Abschnitt bereits das Callback Muster näher betrachtet.
Fliegengewicht Muster
Zweck
Es sollen mit Hilfe des Musters Fliegengewicht große Mengen von Objekten optimal verwendet bzw. verwaltet werden.
Verwendungsgrund
Die durchgehende Verwendung von Objekten ist für Ihre Anwendung grundsätzlich vorteilhaft, die Implementierung führt jedoch zu Schwierigkeiten. Durch das Fliegengewicht Muster, können Sie ein Objekt in unterschiedlich vielen Kontexten verwenden. Dieses Fliegengewicht-Objekt enthält dabei die kontextunabhängigen Informationen und kann nicht von einem anderen Fliegengewicht-Objekt unterschieden werden. Zu diesem Fliegengewicht-Objekt existiert ein weiteres Objekt, welche die kontextabhängigen Informationen beinhaltet.
Vorteile
Das Anlegen von Objekten ist nicht gerade eine sehr performante Angelegenheit und kann mit Hilfe des Fliegengewicht Musters deutlich verringert werden. Dies führt auch in Bezug auf die GarbageCollection zu besseren Zeiten und kann Ihre Anwendung daher beschleunigen.
Nachteile
Mir sind keine Nachteile bekannt. Kennen Sie welche?
Fassade Muster
Das Fassade Mustersermöglicht es sowohl die Anzahl der verteilten Objekte als die Anzahl der Methodenaufrufe an die verteilten Objekte zu verringern. Dieses Muster befasst sich mit dem Problem, dass ein Client viele Methoden auf verteilten Objekten aufruft, um seine Aufgabe zu erfüllen.
Ziel
Die Verwendung des Fassade Musters soll eine einheitliche Schnittstelle zu einem Subsystem bieten. Dabei ist es nicht Aufgabe des Fassade-Objektes Aufgaben selbst zu implementieren. Vielmehr soll die Fassade die Aufgaben an die Objekte des Subsystems weiterleiten. Diese Klassen kennen jedoch die Fassade-Objekt nicht.
Das Process-Entity Muster ermöglicht die Anzahl der Methodenaufrufe auf verteilten Objekten, sowie die Anzahl der verteilten Objekte selbst zu verringern.
Verwendungsgrund
Das Fassade Muster soll, als abstrakte Schnittstelle, die Kopplung zwischen einzelnen Subsystemen verringern. Zusätzlich soll mit Hilfe der Fassade es Fremdsubsystemen möglich sein, ohne Kenntnis über den Aufbau eines Subsystems dieses allgemein verwenden zu können.
Das Process-Entity Muster soll die Anzahl der verteilten Objekte und der Methodenaufrufe auf verteilten Objekten verringern. Zu diesem Zweck wird für eine Aufgabe ein Fassadenobjekt erstellt (Process), welches die Schnittstelle zur Bewältigung der Aufgabe anbietet. Dies ist das einzige verteilte Objekt. Dass Process Objekt übernimmt serverseitig die Aufgabe und delegiert diese an die (nun) lokalen Entity Objekte.
Performancegründe
Für die Verwendung in Netzwerken, können Sie mittels des Fassade Musters die Anzahl der Operationsaufrufe verringern. Bei der Kommunikation über das Netzwerk werden, anstatt mehrere Operationen auf entfernten Objekten eines Subsystems, eine oder wenige Operation des entfernten Fassade-Objektes aufgerufen. Dieses delegiert nunmehr die einzelnen Aufgaben an die lokalen Klassen des Subsystems. Das Process-Entity Muster ist die Umsetzung des Fassade Muster speziell für Netzwerke und wird daher besonders in Zusammenhang mit CORBA und EJB verwendet.
Vorteile
Die Verwendung des Subsystems wird erleichtert, ohne dass Funktionalität verloren geht. Dies wird realisiert, da die Schnittstellen der Subsystemklassen nicht verkleinert werden. Außerdem wird die Netzwerkkommunikation verringert, wodurch der Overhead des entfernten Operationsaufrufes verringert wird. Die Kopplung zwischen den einzelnen Subsystemen kann verringert werden, wodurch die Wartbarkeit der Anwendung erhöht wird.
Nachteile
Es entsteht mehr Bytecode. Als Entwickler des Subsystems, welches die Fassade-Klasse enthält haben Sie mehr Arbeit, da Sie auch die Wartung dieser Klasse übernehmen müssen. Während die Netzwerkgeschwindigkeit steigt, sinkt jedoch durch die Delegation der Aufgabe durch die Fassade an die Objekte des Subsystems die Geschwindigkeit der Ausführung nach außen. Lokale Anwendungen, werden somit etwas langsamer als ohne das Fassade Muster. Dies ist jedoch lokal durch den direkten Zugang an die Objekte des Subsystems lösbar.
Null Pattern
Das Null Pattern kann, wie mit die de.comp.lang.iso-c++ Newsgroup bestätigt hat durchaus für einen Performancegewinn sorgen. Unter Java führt die Verwendung jedoch zu keinen Geschwindigkeitsgewinnen, da die JVM immer strikt gegen null prüft, bevor diese Methoden auf Objekten aufruft – Sie kennen doch die NullPointerException?
Ziel
Das Null Pattern soll vor allem unnötige if then else Verzweigungen vermeiden.
Verwendungsgrund
Damit Operationen / Methoden auf Objekten aufgerufen werden können müssen diese zwangsläufig erst einmal erstellt werden. Als Entwickler können Sie jedoch nicht zwangsläufig davon ausgehen, dass auch immer eine Instanz vorliegt. Das typische Vorgehen ist dabei die Prüfung der Referenz auf null. Dies führt dabei meist zu if then else Blöcken, die den Quelltext schlecht lesbar machen. Um dies zu vermeiden können in vielen Fällen auch Null Objekte angelegt werden. Diese haben üblicherweise nur leere Methodenrümpfe und werfen keine Exception. In einigen Fällen ist es auch möglich dieses Muster mit dem Singleton Muster zu verknüpfen.
Performancegründe
Nicht jede Programmiersprache wird über eine eigene virtuelle Maschine gestartet welche prüft, ob eine Instanz vorliegt auf die die angesprochene Referenz verweist. Hierbei kann es u.U. schneller sein dafür zu sorgen, dass stets eine gültige Referenz vorliegt.
Vorteile
Insbesondere die Lesbarkeit des Quelltextes nimmt zu. Daneben kann aber auch die Ausführungsgeschwindigkeit erhöht werden.
Nachteile
Der Speicherverbrauch erhöht sich durch die vermehrten Objekte. Außerdem müssen Sie beachten, dass im ggf. die Zeit zur Erstellung der Objekte den tatsächlichen Zeitgewinn wettmachen kann. Hier müssen Sie Tests machen.
Process-Entity Muster
Das Process-Entity Muster ist eine spezielle Ausprägung des Fassade Musters. Dabei wird eine Adapterklasse bereitgestellt, die auf dem Server steht und als Ansprechpartner über das Netzwerk zu Verfügung steht. Objekte dieser Klasse delegieren die entfernten Aufrufe ihrer Methoden an die lokalen Objekte und vermindert somit den Netzwerkoverhead.
Singleton Muster
Das Singleton Muster hat den sekundären Zweck die Performance Ihrer Anwendung zu erhöhen.
Ziel
Ein Instanz einer Klasse soll zur Laufzeit nur einmal existieren.
Verwendungsgrund
In bestimmten Fällen ergibt es zur Laufzeit keinen Sinn mehr als eine Instanz einer Klasse zu erzeugen. In diesen Fällen wird das Singleton Muster verwendet um das mehrfache Erzeugen von Instanzen der Klasse zur Laufzeit zu verhindert. Das Singleton Muster ist dabei eine spezielle Art des Fabrikmusters (meist Methoden Fabrik), bei welchem stets das selbe Objekt an den Aufrufer zurückgegeben wird.
Performancegründe
Das Singletonmuster ermöglicht es unnötige Instanzen einer Klasse zu vermeiden. Es ist jedoch nicht unbedingt, auch wenn es der Name ausdrückt, auf eine Instanz beschränkt, sondern kann beliebig erweitert werden, um lediglich eine bestimmte Anzahl von Instanzen zuzulassen. Dies ermöglicht es Ihnen unnötige Speicherverschwendung zu unterbinden.
Vorteile
Der Speicherverbrauch der Anwendung kann bei der Objekterzeugung von bestimmten Klassen gezielt vermindert werden, um unnötige Objekterzeugung zu vermindert. Das Singleton wirkt außerdem wie ein Ein?Objekt?Cache und vermindert daher die Zugriffszeit auf dieses Objekt.
Nachteile
Das Singleton Muster ist ein Erzeugungsmuster. Sie sollten daher überlegen, ob Sie wirklich diese eine Instanz der Klasse benötigen oder direkt mit Klassenoperationen arbeiten können. Dies würde die Zeit für die Objekterstellung einsparen.
Sichtbarkeiten
Jetzt kommen wir in die Teile, die zwar die Performance erhöhen können, jedoch nicht unbedingt besseres Design darstellen.
Die Sichtbarkeiten von Referenzen, also auch der Beziehungen, und der primitiven Datentypen endgültig festzulegen, ist ebenfalls Ihre Aufgabe als Designer. Die Sichtbarkeit kann Ihre Anwendung beschleunigen, da die Zugriffsgeschwindigkeit u.a. von dieser Abhängig ist. Es gibt jedoch neben der Sichtbarkeit auch noch andere Optimierungsmöglichkeiten. Lokale Variablen sind am schnellsten, so dass der Einsatz des Memory Access Pattern hier zu Geschwindigkeitsvorteilen führen kann. Auch Klassenvariablen sind schneller als Variablen auf Objektebene. Dies führt jedoch schon wieder in die OO Abgründe der Performanceoptimierungen.
Lokale Variablen sind in der JVM am schnellsten, da Sie über den jeweiligen Stack abgearbeitet werden und keine Referenz auf das Objekt nötig ist. Außerdem hat die JVM spezielle Bytecodes für den Zugriff auf die ersten vier lokalen Variablen und Parameter (Slot).
Die Zugriffsgeschwindigkeit auf Variablen verringert sich wie folgt:
static => private => final => protected => public
Inlining und Sichtbarkeit
Das Inlining ist eine sehr gute Möglichkeit die Geschwindigkeit Ihrer Anwendung zu optimieren. Der Compiler javac von Sun kann bereits kleine Operationen und Variablen inlinen. Dazu wird die Compilierung mit dem Parameter -o durchgeführt. Damit das Inlining durch den Compiler erfolgen kann, ist jedoch die Sichtbarkeit einzuschränken. Hierbei gilt, dass Variablen, die private sind, sowie private Methoden grundsätzlich optimiert werden können. Konstanten und innere Operationen (Schlüsselwort final) kann der Compiler ebenfalls optimieren.
Vererbungshierarchie
Die Vererbungshierarchie ist ebenfalls ein wichtiger Ansatzpunkt. Als Grundsatz gilt, dass eine flache Klassenhierarchie performanter ist. Natürlich ist dies eine Prüfung des Design und sollte von Ihnen nicht nur aufgrund von Performanceüberlegungen nicht oder unzureichend berücksichtigt werden. Es kann sich jedoch anbieten eine spezialisierte Klasse einer weiteren Vererbung vorzuziehen. Dies bleibt jedoch von Ihnen als Designer im einzelnen zu prüfen.
Insbesondere das Erzeugen von Objekten kann hier zu hohen Geschwindigkeitseinbussen führen. Beim Erzeugen eines Objekts wird üblicherweise der Konstruktor aufgerufen. Der Aufruf eines Konstruktors hat jedoch stets auch den Aufruf eines Konstruktors in jeder Superklasse zur Folge. Dies zieht entsprechende Folgen nach sich. Sinnvoll ist es daher ebenfalls möglichst wenig - besser noch gar keine Funktionalität in den Standardkonstruktor zu legen.
Ein kleines Beispiel hierzu verdeutlicht die Aufrufkette, welche entsteht bei einer kleinen Vererbungshierarchie. Der Aufruf des Standardkonstruktor muss dabei nicht explizit angegeben werden.
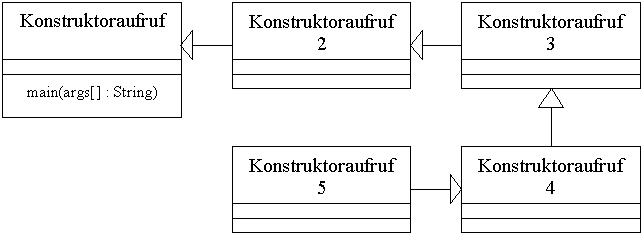
package bastie.performance.vererbung;
public class Konstruktoraufruf extends Konstruktoraufruf2{
public Konstruktoraufruf() {
System.out.println(Konstruktoraufruf.class);
}
public static void main(String [] args){
Konstruktoraufruf k = new Konstruktoraufruf();
}
}
class Konstruktoraufruf2 extends Konstruktoraufruf3{
public Konstruktoraufruf2() {
System.out.println(Konstruktoraufruf2.class);
}
}
class Konstruktoraufruf3 extends Konstruktoraufruf4{
public Konstruktoraufruf3() {
System.out.println(Konstruktoraufruf3.class);
}
}
class Konstruktoraufruf4 extends Konstruktoraufruf5{
public Konstruktoraufruf4() {
System.out.println(Konstruktoraufruf4.class);
}
}
class Konstruktoraufruf5 {
public Konstruktoraufruf5() {
System.out.println(Konstruktoraufruf5.class);
}
}
Beim Start der Klasse Kontrukotoraufruf erhalten Sie nun diese Ausgabe:
class bastie.performance.vererbung.Konstruktoraufruf5
class bastie.performance.vererbung.Konstruktoraufruf4
class bastie.performance.vererbung.Konstruktoraufruf3
class bastie.performance.vererbung.Konstruktoraufruf2
class bastie.performance.vererbung.Konstruktoraufruf
Antidesign
Die Überschrift Antidesign ist vielleicht etwas hart, drückt jedoch gut aus, welche Betrachtungen wir im folgenden Anstellen.
Direkter Variablenzugriff
Der direkte Variablenzugriff ist eine Möglichkeit die letzten Geschwindigkeitsoptimierungen aus Ihrer Anwendung herauszukitzeln. Dabei rufen andere Objekte nicht mehr die Zugriffsoperationen auf, um die Informationen von einem bestimmten Objekt zu erfragen, sondern nehmen sich die Informationen direkt.
Dies widerspricht dem OO Gedanken der Kapselung derart, dass ich hier nicht näher darauf eingehen möchte. Da jedoch der Overhead des Operationsaufrufes hier wegfällt, ist diese Zugriffsart schneller. Sie müssen jedoch alle Referenzen / primitive Datentypen hierfür mit der Sichtbarkeit „public“ belegen.
Vermischung von Model und View
Hier gilt ähnliches wie bei dem direkten Variablenzugriff. Sofern Sie Model und View nicht trennen, sondern dies innerhalb eines einzigen Objektes gestalten erhalten Sie eine schnellere Anwendung. Hier entfällt neben dem Methodenaufruf (innerhalb einer Klasse, können Sie ja auch nach dem OO Ansatz direkt auf die Informationen zugreifen) auf das Erstellen des zweiten Objektes und der Zugriff auf dieses.
Dies ist nicht so weit herbeigezogen, wie Sie vielleicht denken. Die java.awt.List hält, wie alle AWT Klassen auch die Daten in sich. Die javax.swing.JList hingegen trennt die Repräsentation von dem eigentlichen Modell (javax.swing.ListModel).
Teil 4
Inhaltsverzeichnis
Teil 6
all rights reserved © Bastie - Sebastian Ritter @:
w³: http://www.Bastie.de
Diese Seite ist Bestandteil der
Internetpräsenz unter http://www.Bastie.de
Java
Cobol
Software
Resourcen
Service
Links
Über mich
Zum Gästebuch
Forum